Robust DL/ML
In general, robust deep learning covers: missing labels (semisupervised learning); noisy labels (noise detection and correction); regularisation techniques; sample imbalance (long-tailed class distribution); adversarial learning; and so on.
Remark: in my reading notes, sometimes I simply quote texts directly from the original paper. Therefore, `we’ means a paper’s authors in many contexts.
- Label noise
- The design of loss functions (i.e., optimisation objectives or output regularistion)
- Semi-supervised learning
- Others
Label noise
-
In the presence of noisy or incorrect labels, neural networks have the undesirable tendency to memorize information about the noise. Standard regularization techniques such as dropout, weight decay or data augmentation sometimes help, but do not prevent this behavior.
If one considers neural network weights as random variables that depend on the data and stochasticity of training, the amount of memorized information can be quantified with the Shannon mutual information between weight and the vector of all training labels given inputs \(I(w;y\|x)\).
We show that for any training algorithm, low values of this term correspond to reduction in memorization of label-noise and better generalization bounds.-
Drawback: An auxiliary network is used to detect incorrect or misleading labels.
- Simpler method: DM and IMAE
- Simpler method: ProSelfLC
-
There is a concurrent comprehensive analysis about label smoothing/manipulation: ProSelfLC
We present a novel connection of label smoothing to loss correction techniques from the label noise literature; We empirically demonstrate that label smoothing significantly improves performance under label noise at varying noise levels, and is competitive with loss correction techniques.
We explain these denoising effects by relating label smoothing to l2 regularisation.
While Mülleret al. (2019) established that label smoothing can harm distillation, we show an opposite picture in noisy settings. We show that when distilling from noisy labels, smoothing the teacher improves the student; this is in marked contrast to recent findings in noise-free settings.
-
“Webly-labeled” images are commonly used in the literature (Bootkrajang & Kab ́an,2012; Li et al., 2017a; Krause et al., 2016; Chen & Gupta,2015), in which both images and labels are crawled fromthe web and the noisy labels are automatically determined by matching the images’ surrounding text to a class name during web crawling or equivalently by querying the search index afterward. Unlike synthetic labels, web labels follow a realistic label noise distribution but have not been studied in a controlled setting.
First, we establish the first benchmark of controlled web label noise, where each training example is carefully annotated to indicate whether the label is correct or not. Specifically, we automatically collect images by querying Google Image Searchusing a set of class names, have each image annotated by3-5 workers, and create training sets of ten controlled noiselevels. As the primary goal of our annotation is to identify images with incorrect labels, to obtain a sufficient numberof these images we have to collect a total of about 800,000 annotations over 212,588 images. The new benchmark enables us to go beyond synthetic label noise and study weblabel noise in a controlled setting. For convenience, we will refer it as web label noise (or red noise) to distinguish itfrom synthetic label noise (or blue noise).
- Second, this paper introduces a simple yet highly effective method to overcome both synthetic and real-world noisy labels. It is based on a new idea of minimizing the empirical vicinal risk using curriculum learning. We show that it consistently outperforms baseline methods on our datasets and achieves state-of-the-art performance on two public benchmarks of synthetic and real-world noisy labels. Notably, on the challenging benchmark WebVision 1.0 (Li et al., 2017a)that consists of 2.2 million images of real-world noisy labels,it yields a significant improvement of 3% in the top-1 accu-racy, achieving the best-published result under the standard training setting.
- MentorMix: to design a new robust loss to overcome noisy labels using curriculum learning and vicinal risk minimization
- MentorNet: curriculum learning
- Mixup: data augmentation
Finally, we conduct the largest study by far into understanding DNNs trained on noisy labels across a variety of noise types (blue and red), noise levels, training settings, and network architectures.
- We hope our (i) benchmark, (ii) new method, and (iii) findings will facilitate future deep learning research on noisy labeled data. We will release our data and code.
-
(arXiv-20-June) Early-Learning Regularization Prevents Memorization of Noisy Labels
- Their analysis is similar with DM and IMAE, and they forgot to cite them in their first released version.
- Early in training, the gradients corresponding to the correctly labeled examples dominate the dynamics—leading to early progress towards the true optimum—but that the gradients corresponding to wrong labels soon become dominant—at which point the classifier simply learns to fit the noisy labels.
- There are two key elements to our approach. (A regularization term that incorporates target probabilities estimated from the model outputs using several semi-supervised learning techniques.)
- First, we leverage semi-supervised learning techniques to produce target probabilities based on the model outputs.
- Second, we design a regularization term that steers the model towards these targets, implicitly preventing memorization of the false labels.
- We also perform a systematic ablation study to evaluate the different alternatives to compute the target probabilities, and the effect of incorporating mixup data augmentation.
- Temporal ensembeling: averaging label predictions;
- MeanTeachers: Weight-averaged consistency targets
- MixMatch => DivideMix
- Consistency regularisation: Interpolation Consistency Training
- Their analysis is similar with DM and IMAE, and they forgot to cite them in their first released version.
-
Error-Bounded Correction of Noisy Labels, Songzhu Zheng, Pengxiang Wu, Aman Goswami, Mayank Goswami, Dimitris Metaxas, Chao Chen
To be robust against label noise, many successful methods rely on the noisy classifiers (i.e., models trained on the noisy training data) to determine whether a label is trustworthy. However, it remains unknown why this heuristic works well in practice.
In this paper, we provide the first theoretical explanation for these methods.
We prove that the prediction of a noisy classifier can indeed be a good indicator of whether the label of a training data is clean.
Based on the theoretical result, we propose a novel algorithm that corrects the labels based on the noisy classifier prediction. The corrected labels are consistent with the true Bayesian optimal classifier with high probability.
We prove that when the noisy classifier has low confidence on the label of a datum, such label is likely corrupted. In fact, we can quantify the threshold of confidence, below which the label is likely to be corrupted, and above which is it likely to be not. We also empirically show that the bound in our theorem is tight.
We provide a theorem quantifying how a noisy classifier’s prediction correlates to the purity of a datum’s label. This provides theoretical explanation for data-recalibrating methods for noisy labels.
Inspired by the theorem, we propose a new label correction algorithm with guaranteed success rate.
A Bayes optimal classifier is the minimizer of the risk over all possible hypotheses.
We also have a burn-in stage in which we train the networkusing the original noisy labels for \(m\) epochs. During theburn-in stage, we use the original cross-entropy loss;
After the burn-in stage, we want to avoid overfitting of theneural network. To achieve this goal, we introduce aretroactive loss term. The idea is to enforce the consistency between \(f\) and the prediction of the model at a previous epoch.
In all experiments, we use early stopping on validation set to tune hyperparameters and report theperformance on test set.
Simple and Effective ProSelfLC: Progressive Self Label Correction
-
Deep k-NN for Noisy Labels Dara Bahri, Heinrich Jiang, Maya Gupta
In this paper, we provide an empirical study showing that a simple k-nearest neighbor-based filtering approach on the logit layer of a preliminary model can remove mislabeled training data and produce more accurate models than many recently proposed methods.
We use a deep k-NN, in that we use a k-NN on learned intermediate rep-resentations of a preliminary model to identify suspicious examples for filtering.-
After identifying examples whose labels disagree with their neighbors, one can either automatically remove them, or send them to a human operator for further review. This strategy can also be useful in human-in-the-loop systems where one can warn the human annotator that a label is suspicious and automatically propose new labels based on its nearest neighbors.
- This is suspicious in that a softmax classifier is based on similarities (logits), then why not using the predictions directly as done in ProSelfLC?
Theoretically, we show that k-NN’s predictions will, asymptotically, only identify a training example as clean if its label is the Bayes-optimal label.
- We also provide finite-sample analysis in terms of the margin and how spread-out the corrupted labels are (Theorem 1), rates of convergence for the margin (Theorem 2) and rates under Tsybakov’s noise condition (Theorem 3) with all rates matching minimax-optimal rates in the noiseless setting.
-
This work is motivated by DM and IMAE
We provide new theoretical insights into robust loss func-tions demonstrating that a simple normalization can makeany loss function robust to noisy labels.
We identify that existing robust loss functions suffer from an underfitting problem. To address this, we propose ageneric framework Active Passive Loss(APL) to build new loss functions with theoretically guaranteed robustness and sufficient learning properties.
Robustness and Convergence?
-
We propose stochastic integrated gradient underweighted ascent (SIGUA): in a mini-batch, we adopt gradient descent on good data as usual, and learning-rate-reduced gradient ascent on bad data;
Technically, SIGUA pulls optimization back for generalization when their goals conflict with each other;
- Philosophically, SIGUA shows forgetting undesired memorization can reinforce desired memorization.
- The idea is similar with DM and IMAE
- Almost the same authors as Searching to Exploit Memorization Effect in Learning with Noisy Labels QUANMING YAO, Hansi Yang, Bo Han, Gang Niu, James Kwok
-
Sample selection approaches: select \(R(t)\) small-loss samples based on network’s predictions
Formulation as an AutoML Problem (complex algorithm personally);
Bi-level optimisation
No sample selection is needed: DM and IMAE
Almost the same authors as SIGUA: Forgetting May Make Learning with Noisy Labels More Robust Bo Han, Gang Niu, Xingrui Yu, QUANMING YAO, Miao Xu, Ivor Tsang, Masashi Sugiyama
-
 Variational Label Enhancement, Ning Xu, Jun Shu, Yun-Peng Liu, Xin Geng
Variational Label Enhancement, Ning Xu, Jun Shu, Yun-Peng Liu, Xin GengThe learning process on the instances labeled by label distributions is called label distribution learning (LDL).
Unfortunately, many training sets only contain simple logical labels rather than label distributions due to the difficulty of obtaining the label distributions directly.
This is consistent with the label definition in ProSelfLC

-
Peer Loss Functions: Learning from Noisy Labels without Knowing Noise Rates, Yang Liu, Hongyi Guo
Overall, this method is complex due to peer samples.
The motivation/highlight is not novel: without Knowing Noise Rates. Our main goal is to provide an al-ternative that does not require the specification of the noiserates, nor an additional estimation step for the noise.
Peer loss is invariant to label noise when optimizing with it. This effect helps us get rid of theestimation of noise rates.
i) is robust to asymmetriclabel noise with formal theoretical guarantees and ii) requires no prior knowledge or estimationof the noise rates (no need for specifying noise rates).
We also provide preliminary results on how peer loss generalizes to multi-class clas-sification problems.
Relevant work 1: neurips-19: \(L_{DMI}\): A Novel Information-theoretic Loss Functionfor Training Deep Nets Robust to Label Noise To the best ofour knowledge, \(L_{DMI}\) is the first loss function that is provably robust to instance-independent label noise, regardless of noise pattern, and it can be applied to any existing classification neural networks straightforwardly without any auxiliary information. In addition to theoretical justification, we also empirically show that using \(L_{DMI}\) outperforms all other counterparts in the classification task on both image dataset and natural language dataset include Fashion-MNIST, CIFAR-10, Dogs vs. Cats, MR with a variety of synthesized noise patterns and noise amounts,as well as a real-world dataset Clothing1M. The core of \(L_{DMI}\) is a generalized version of mutual information, termed Determinant based Mutual Information (DMI), which is not only information-monotone but also relatively invariant.
Relevant work 2: Water from Two Rocks: Maximizing the Mutual Information
No loss function is needed: DM and IMAE
-
Binary classification => Not highly generic.
Specifically, we introduce the concept of distilled examples, i.e. examples whose labels are identical with the labels assigned for them by the Bayes optimal classifier, and prove that under certain conditions classifiers learnt on distilled examples will converge to the Bayes optimal classifier.
Inspired by the idea of learning with distilled examples, we then propose a learning algorithm with theoretical guarantees for its robustness to BILN.
-
-
https://openreview.net/forum?id=HJgExaVtwr¬eId=keqS67sTCbi
Exploiting MixMatch;
The algorithm is complex. Instead, DM, IMAE, and ProSelfLC are much simpler.
DivideMix models the per-sample loss distribution with a mixture model to dynamically divide the training data into a labeled set with clean samples and an unlabeled set with noisy samples, and trains the model on both the labeled and unlabeled data in a semi-supervised manner.
To avoid confirmation bias, we simultaneously train two diverged networks where each network uses the dataset division from the other network. During the semi-supervised training phase, we improve the MixMatch strategy by performing label co-refinement and label co-guessing on labeled and unlabeled samples, respectively.
DivideMix discards the sample labels that are highly likely to be noisy, and leverages the noisy samples as unlabeled data to regularize the model from overfitting and improve generalization performance.
For labeled samples, we refine their ground-truth labels using the network’s predictions guided by the GMM for the other network. For unlabeled samples,we use the ensemble of both networks to make reliable guesses for their labels.
-
Training two networks, Co-divide datasets, label co-refinement and co-guessing.
- improving MixMatch with label co-refinement and co-guessing.
-
The design of loss functions (i.e., optimisation objectives or output regularistion)
-
Improved Training Speed, Accuracy, and Data Utilization Through Loss Function Optimization
Speed, Accuracy, Data Efficiency, etc;
- BAIKAL loss;
- Genetic Loss Function Optimization (GLO) builds loss functions hierarchically from a set of operators and leaf nodes;
- A general framework for loss function metalearning, covering both novel loss function discovery and optimization, is developed and evaluated experimentally.
- No loss function is needed: DM and IMAE
-
- We try to investigate how particular choices of loss functions affect deep models and their learning dynamics, as well as resulting classifiers robustness to various effects;
- We present new insights into theoretical properties of a couple of these losses;
- We provide experimental evaluation of resulting models’ properties, including the effect on speed of learning, final performance, input data and label noise robustness as well as convergence.
- So why is using these two loss functions (\(L_1\), \(L_2\) losses) unpopular? Is there anything fundamentally wrong with this formulation from the mathematical perspective? While the following observation is not definitive, it shows an insight into what might be the issue causing slow convergence of such methods.
- Lack of convexity comes from the same argument since second derivative wrt. to any weight in the final layer of the model changes sign (as it is equivalent to first derivative being non-monotonic).
Proposition 2. \(L_1\), \(L_2\) losses applied to probabilities estimates coming from sigmoid (or softmax) have non-monotonic partial derivatives wrt. to the output of the final layer (and the loss is not convex nor concave wrt. to last layer weights). Furthermore, they vanish in both infinities, which slows down learning of heavily misclassified examples.
- No loss function is needed: DM and IMAE
Semi-supervised learning
(CVPR-19) Ahmet Iscen et al Label Propagation for Deep Semi-supervised Learning
-
ICT encourages the prediction at an interpolation of unlabeled points to be consistent with the interpolation of the predictions at those points.
In classification problems, ICT moves the decision boundary to low-density regions of the data distribution.
MixUp is used for preprocessing/data augmentation.
-
- This method is simple and effective. Their writing is also extremely naive to understand, instead of being fancy.
- Many recent approaches for semi-supervised learning add a loss term which is computed on unlabeled data and encourages the model to generalize better to unseen data:
- entropy minimization – which encourages the model to output confident predictions on unlabeled data;
- consistency regularization – which encourages the model to produce the same output distribution when its inputs are perturbed;
- generic regularization – which encourages the model to generalize well and avoids overfitting the training data.
- We introduce MixMatch, an SSL algorithm which introduces a single loss that gracefully unifies these dominant approaches to semi-supervised learning. We further show in an ablation study that MixMatch is greater than the sum of its parts;
- https://github.com/google-research/mixmatch
In short, MixMatch introduces a unified loss term for unlabeled data that seamlessly reduces entropy while maintaining consistency and remaining compatible with traditional regularization techniques.
Label guessing process used in MixMatch:
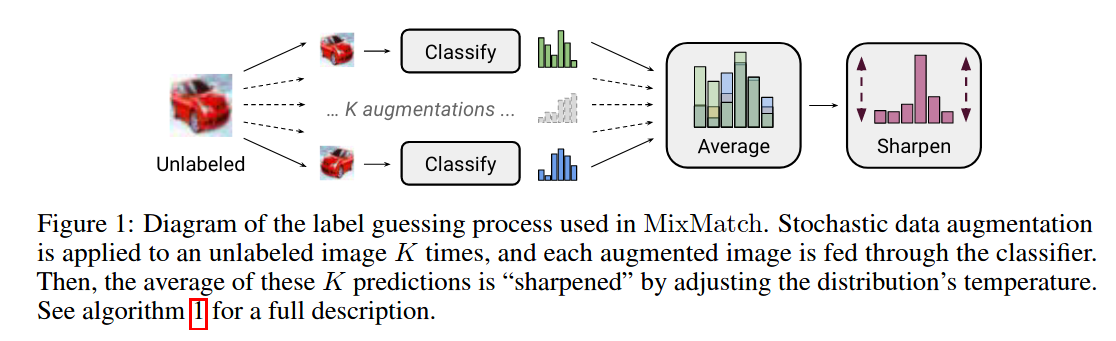
Question: if hyperparameters are not sensitive, why do we need it? Therefore, this writing is just for reviewers, not for readers.

To set the stage for MixMatch, we first introduce existing methods for SSL. We focus mainly on those which are currently state-of-the-art and thatMixMatchbuilds on; there is a wide literature onSSL techniques that we do not discuss here (e.g., “transductive” models [14,22,21], graph-based methods [49,4,29], generative modeling [3,27,41,9,17,23,38,34,42], etc.). More comprehensive overviews are provided in [49,6].
- MixUp is used for preprocessing/data augmentation.
-
-
https://openreview.net/forum?id=HJgExaVtwr¬eId=keqS67sTCbi
- Exploiting MixMatch;
- The algorithm is complex. Instead, DM, IMAE, and ProSelfLC are much simpler.
DivideMix models the per-sample loss distribution with a mixture model to dynamically divide the training data into a labeled set with clean samples and an unlabeled set with noisy samples, and trains the model on both the labeled and unlabeled data in a semi-supervised manner.
To avoid confirmation bias, we simultaneously train two diverged networks where each network uses the dataset division from the other network. During the semi-supervised training phase, we improve the MixMatch strategy by performing label co-refinement and label co-guessing on labeled and unlabeled samples, respectively.
DivideMix discards the sample labels that are highly likely to be noisy, and leverages the noisy samples as unlabeled data to regularize the model from overfitting and improve generalization performance.
For labeled samples, we refine their ground-truth labels using the network’s predictions guided by the GMM for the other network. For unlabeled samples,we use the ensemble of both networks to make reliable guesses for their labels.
- Training two networks, Co-divide datasets, label co-refinement and co-guessing.
- improving MixMatch with label co-refinement and co-guessing.
-
https://openreview.net/forum?id=HJgExaVtwr¬eId=keqS67sTCbi
-
- Because the targets change only onceper epoch, Temporal Ensembling becomes unwieldy when learning large datasets.
- To overcome this problem, we propose Mean Teacher, a method that averages model weights instead of label predictions. As an additional benefit, Mean Teacher improves test accuracy and enables training with fewer labels than Temporal Ensembling.
Abstract: Without changing the network architecture, Mean Teacher achieves anerror rate of 4.35% on SVHN with 250 labels, outperforming Temporal Ensembling trained with 1000 labels. We also show that a good network architecture is crucialto performance. Combining Mean Teacher and Residual Networks, we improve the state of the art on CIFAR-10 with 4000 labels from 10.55% to 6.28%, and on ImageNet 2012 with 10% of the labels from 35.24% to 9.11%.
Key algorithm:

There are at least two ways to improve the target quality. One approach is to choose the perturbation of the representations carefully instead of barely applying additive or multiplicative noise. Another approach is to choose the teacher model carefully instead of barely replicating the student model.Concurrently to our research, “Virtual Adversarial Training” (VAT) has taken the first approach and shown that Virtual Adversarial Training can yield impressive results. We take the second approach and will show that it too provides significant benefits. To our understanding, these two approaches are compatible, andtheir combination may produce even better outcomes. However, the analysis of their combined effectsis outside the scope of this paper.
- About TEMPORALENSEMBLING FORSEMI-SUPERVISEDLEARNING: Each target is updated only once per epoch, the learned information is incorporated into the training process at a slow pace. The larger the dataset, the longer the span of the updates, and in the case of on-line learning, it is unclear how Temporal Ensembling can be used at all. (One could evaluate all the targets periodically more than once per epoch, but keeping the evaluation span constant would require \(O(n^2)\) evaluations per epoch where n is the number of training examples.)
-
- We introduce self-ensembling, where we form a consensus prediction of the unknown labels using the outputs of the network-in-training on differentepochs, and most importantly, under different regularization and input augmentation conditions. This ensemble prediction can be expected to be a better predictorfor the unknown labels than the output of the network at the most recent training epoch, and can thus be used as a target for training;
-
- While existing variants of BNNs are able to produce reliable, albeit approximate, uncertainty estimates over in-distribution data, it has been shown that they tend to be overconfident in predictions made on target data whose distribution over features differs from the training data, i.e., the covariate shift setup.
- We develop an approximate Bayesian inference scheme based on posterior regularisation, where we use information from unlabelled target data to produce more appropriate uncertainty estimates for ‘‘covariate-shifted’’ predictions.
-
Empirical evaluations demonstrate that our method performs competitively compared to Bayesian and frequentist approaches to uncertainty estimation in neural networks.
uncertainty estimation: quantifying confidence in their predictions — this is crucial in high-stakes applications that involve critical decision-making.
We make the following observation: a point being in the target data is an indication that the model should output higher uncertainty because the target distribution is not well-represented by training data due to covariate shift. We use whether the data come from training or target set as a “pseudo-label”of model confidence.
BNN learns a posterior distribution over parametersthat encapsulates the model uncertainty. Due the complexityof deep neural networks, the exact posterior is usually intractable. Hence, much of the research in BNN literature is devoted to finding better approximate inference algorithms for the posterior.
We note that most existingworks in SSL focus entirely on using unlabelled data toimprove predictive performance (e.g. accuracy), but muchless thoughts have been given to improving the uncertainty estimate for those predictions, which is the focus of this paper.
-
Semi-supervised Learning: Many recent works encourage the model to generalise better by using a regularisation term computed on the unlabelled data MixMatch Berth-elot et al. (NeurIPS 2019).
-
Consistency regularization applies data augmentation to semi-supervised learning by leveraging the idea that a classifier should output the same class distribution for an unlabeled example even after it has been augmented.
- E.g. 1: (TPAMI 2018) “Virtual Adversarial Training” (VAT) addresses this by instead computing an additive perturbation to apply to the input which maximally changes the output class distribution;
- E.g. 2: (NeurIPS 2017) “Mean Teacher”: a method that averages model weights instead of label predictions. uses an exponential moving average of model parameter values. This provides a more stable target and was found empirically to significantly improve results. Mean Teacher improves test accuracy and enables training with fewer labels than Temporal Ensembling. Combining Mean Teacher and Residual Networks, we improvethe state of the art on CIFAR-10 with 4000 labels from 10.55% to 6.28%, and on ImageNet 2012 with 10% of the labels from 35.24% to 9.11%.
- E.g. 3: MixMatch Berth-elot et al. (NeurIPS 2019) utilizes a form of consistency regularization through the use of standard data augmentation for images (random horizontal flips and crops).
- Connections: There are at least two ways to improve the target quality. One approach is to choose the perturbation of the representations carefully instead of barely applying additive or multiplicative noise. Another approach is to choose the teacher model carefully instead of barely replicating the student model.Concurrently to our research, “Virtual Adversarial Training” (VAT) has taken the first approach and shown that Virtual Adversarial Training can yield impressive results. We take the second approach and will show that it too provides significant benefits. To our understanding, these two approaches are compatible, andtheir combination may produce even better outcomes. However, the analysis of their combined effectsis outside the scope of this paper.
- About TEMPORALENSEMBLING FORSEMI-SUPERVISEDLEARNING: Each target is updated only once per epoch, the learned information is incorporated into the training process at a slow pace. The larger the dataset, the longer the span of the updates, and in the case of on-line learning, it is unclear how Temporal Ensembling can be used at all. (One could evaluate all the targets periodically more than once per epoch, but keeping the evaluation span constant would require \(O(n^2)\) evaluations per epoch where n is the number of training examples.)
Entropy Minimization: CCE, ProSelfLC, (NeurIPS) Semi-supervised learning by entropy minimization, (ICML workshop 2013) Pseudo-Label
Traditional Regularization: weight decay, MixUP, etc.
- More work on semi-supervised learning:
- (NeurIPS 2018) Entropy minimisation: Jean, N., Xie, S. M., and Ermon, S. Semi-supervised deep kernel learning: Regression with unlabeled data by minimizing predictive variance.
- (NeurIPS 2016) Consistency regularisation: Sajjadi, M., Javanmardi, M., and Tasdizen, T. Regulariza-tion with stochastic transformations and perturbations fordeep semi-supervised learning.
- (IJCAI 20019) Consistency regularisation: Interpolation Consistency Training for Semi-supervised Learning Vikas Verma, Alex Lamb, Juho Kannala, Yoshua Bengio, and David Lopez-Paz
-
Consistency regularization applies data augmentation to semi-supervised learning by leveraging the idea that a classifier should output the same class distribution for an unlabeled example even after it has been augmented.
-
- The need to address the degeneracy of Laplacian semi-supervised learning
- Geometric or topological structure in unlabeled data can be used
- The exact nature of the degeneracy in Laplace learning, and the question of how the tails of the spikes propagate label information, has not been studied and is still poorly understood.
- We carefully analyze Laplace learning at very low label rates, and we discover that nearly all of the degeneracy of Laplace learning is due to a large constant bias in the solution of the Laplace equation that is present only at low label rates. In order to overcome this problem we introduce a new algorithm, we call Poisson learning
-
- The performance is seriously decreased when the class distribution is mismatched, among which the common situation is that unlabeled data contains some classes not seen in the labeled data.
Semi-Supervised Learning Using Gaussian Fields and Harmonic Functions
Others
-
In this work,we propose a strategy for building linear classifiers that are certifiably robust against a strong variant of label flipping, where each test example is targeted independently.
For each test point, our classifier includes a certification that its prediction would be the same had some number of training labels been changed adversarially.We generalize our results to the multi-class case, providing the first multi-class classification algorithm that is certifiably robust to label-flipping attacks.
we propose a pointwise certified defense—this means that with each prediction, the classifier includes a certification guaranteeing that its prediction would not be different had it been trained on data with some number oflabels flipped.
Prior works on certified defenses make statistical guarantees over the entire test distribution (rather than at the population level), but they make no guarantees as to the robustness of a predictionon any particular test point; thus, a determined adversary could still cause a specific test point to be misclassified.
We therefore consider the threat of a worst-case adversary that can make a training set perturbation to target each test point individually.
-
Adversarial robustness: Robustness May Be at Odds with Accuracy
We show that adversarial robustness might come at the cost of standard classification performance, but also yields unexpected benefits. We show that there exists an inherent tension between the goal of adversarial robustness and that of standard generalization. Specifically, training robust models may not only be more resource-consuming, but also lead to a reduction of standard accuracy.
Unexpected benefits: the features learned by robust models tend to align better with salient data characteristics and human perception.
Rebuttal: The aim of our paper is to demonstrate an inherent trade off between robustness and standard accuracy in a concrete setting. We believe that exhibiting the tradeoff in a simple and natural setting is a strength rather than a weakness of our paper, since such simple settings can manifest as special cases of more complex settings.
Thus the trade-off discussed in the paper would manifest as long as there are some non-robust features which contribute to the accuracy of the standard model.Rebuttal: We want to emphasize that our goal is to understand and theoretically demonstrate the standard vs. robust accuracy tradeoffs observed in practice (reported multiple times in prior work as we discuss in our paper, as well as in the suggested paper). We are not claiming to be the first ones to observe tradeoffs of this nature empirically, but we are the first to provide some insight into its roots.
At the root of this trade-off is the fact that features learned by the optimal standard and optimal robust classifiers are fundamentally different and, interestingly, this phenomenon persists even in the limit of infinite data.Adversarially robust learning tends to equip the resulting models with invariances that we would expect to be also present in human vision. This, in turn, leads to features that align better with human perception, and could also pave the way towards building models that are easier to understand.
-
- Partial-label learning is one of the important weakly supervised learning problems, where each training example is equipped with a set of candidate labels that contains the true label.
-
State-of-the-art domain adaptation methods make use of deep networks to extract domain-invariant representations.
Existing methods assume that all the instances in the source domain are correctly labeled; while in reality, it is unsurprising that we may obtain a source domain with noisy labels.
In this paper, we are the first to comprehensively investigate how label noise could adversely affect existing domain adaptation methods in various scenarios.
Further, we theoretically prove that there exists a method that can essentially reduce the side-effect of noisy source labels in domain adaptation.
-
- How can we effectively utilize the transformation-based self-supervision for fully-supervised classification tasks?