For any specific discussion or potential future collaboration, please feel free to contact me. As a young researcher, your interest and star (citation) will mean a lot for me and my collaborators. Paper link: https://arxiv.org/abs/2005.03788
Cite our work kindly if you find it useful: @inproceedings{wang2021proselflc, title={ {ProSelfLC}: Progressive Self Label Correction for Training Robust Deep Neural Networks}, author={Wang, Xinshao and Hua, Yang and Kodirov, Elyor and Clifton, David A and Robertson, Neil M}, booktitle={CVPR}, year={2021} }
Human annotations contain bias, subjectiveness, and errors.
Therefore, some prior work penalises low-entropy statuses => so that wrong fitting is alleviated in some degree. Representative proposals are label smoothing and confidence penalty.
Our new finding on Entropy Minimisation:
We can solve it still by minimum entropy regularisation principle;
Diverse minimum-entropy statuses exist (e.g., when a learner perfectly fits random labels, the entropy also reaches a minimum):
The minimum-entropy status defined by untrusted human-annotated labels is incorrect, thus leading to poor generalisation. CCE => Non-meaningful minimum-entropy status => poor generalisation.
We propose to redefine a more meaningful minimum-entropy status by exploiting the knowledge of a learner itself, which shows promising results. Label correction => Meaningful low-entropy status => good generalisation.
We highlight ProSelfLC’s Underlying Principle is ‘‘Contradictory’’ with: Maximum-Entropy Learning, Confidence Penalty and Label Smoothing, which are popular recently. Then we wish our community think critically about two principles:
Rewarding a correct low-entropy status (ProSelfLC)
Penalising a non-meaningful low-entropy status (CCE+LS, or CCE+CP)
In our experiments: ProSelfLC > (CCE+LS, or CCE+CP) > CCE
Being contradictory in entropy, both help but their angles differ:
CCE fits non-meaningful patterns => LS and CP penalise such fitting;
CCE fits non-meaningful patterns => ProSelfLC first corrects them => then fits.
Should we trust and exploit a learner’s knowledge as training goes, or always trust human annotations?
As a learner, to trust yourself or supervison/textbooks?
The answer should depend on what a learner has learned.
Should we optimise a learner towards a correct low-entropy status, or penalise a low-entropy status?
As a supervisor/evaluator, to reward or penalise a confident learner?
Open discussion: we show it’s fine for a learner to be confident towards a correct low-entropy status. Then more future research attention should be paid to the definition of correct knowledge, as in general we accept, human annotations used for learning supervision may be biased, subjective, and wrong.
As a supervisor, before training multiple learners, to think about how to train one great learner first?
1st context: recently, many techniques about training multiple learners (co-training, mutual learning, knowledge distillation, adversarial training, etc) have been proposed.
2nd context: in our work, we work on how to train single learner better.
1st personal comment: training multiple learners is much more expensive and complex;
2nd personal comment: when training multiple learners collaboratively, if one learner does not perform well, it tends to hurt the other learners.
Noticeable Findings
Rewarding low entropy (towards a meaningful status) leads to better generalisation than penalising low entropy.
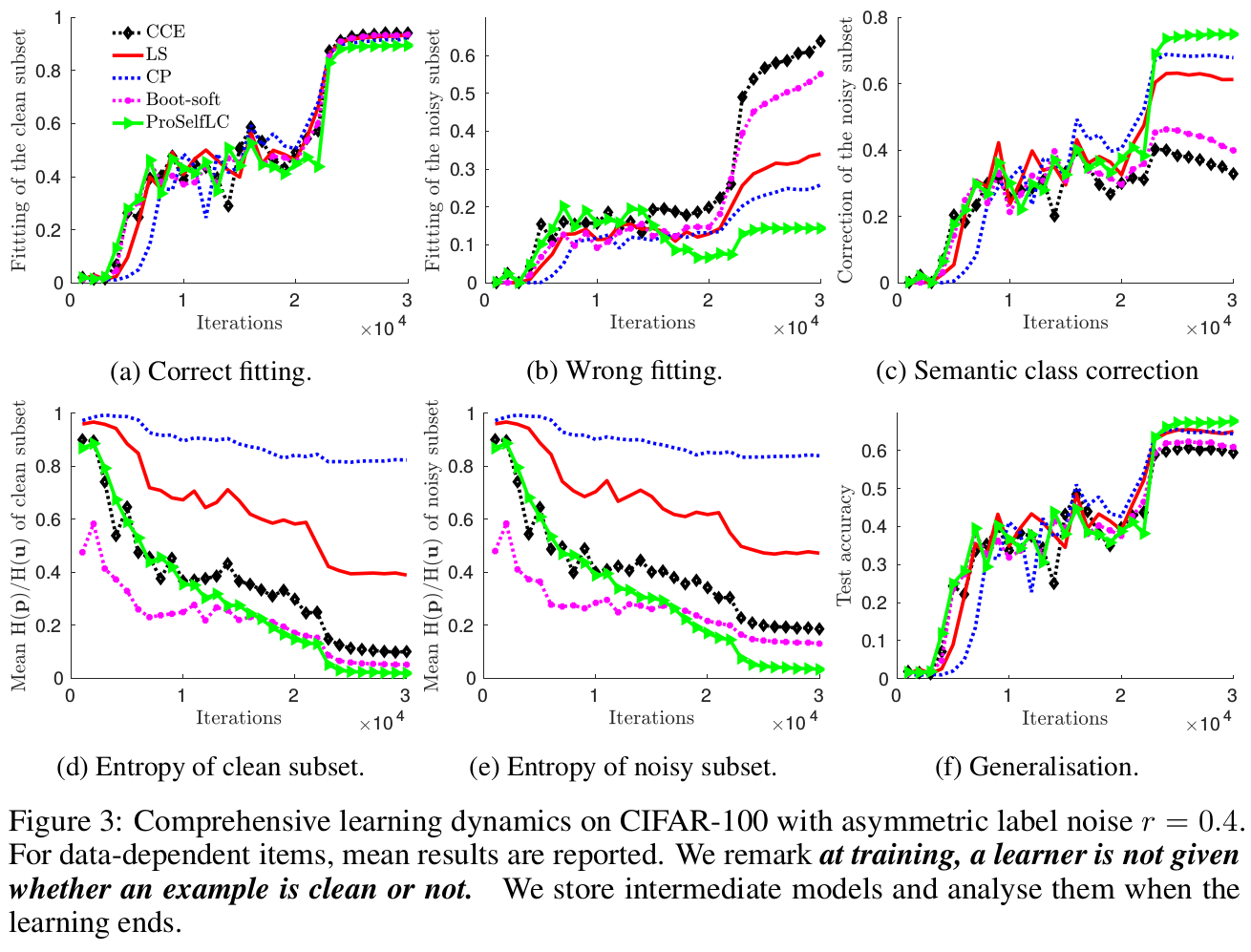
Comprehensive learning dynamics for thorough understanding of learning behaviours.
Result analysis:
Revising the semantic class and perceptual similarity structure. Generally, the semantic class of an example is defined according to its perceptual similarities with training classes, and is chosen to be the most similar class. In Figure 3b and 3c, we show a learner’s behaviours on without fitting wrong labels and correcting them in different approaches. We remark that ProSelfLC performs the best.
To reward or penalise low entropy? LS and CP are proposed to penalise low entropy. On the one hand, we observe that LS and CP work, being consistent with prior evidence. As shown in Figure 3d and 3e, the entropies of both clean and noisy subset are the largest in LS and CP, and correspondingly their generalisation performance is the best except for ProSelfLC in Figure 3f. On the other hand, our ProSelfLC has the lowest low entropy while performs the best, which demonstrates it does not hurt for a learner to be confident. However, a learning model needs to be careful about what to be confident in. Let us look at Figure 3b and 3c, ProSelfLC has the least wrong fitting while the highest semantic class correction rate, which denotes it is confident in learning meaningful patterns.
Literature Review
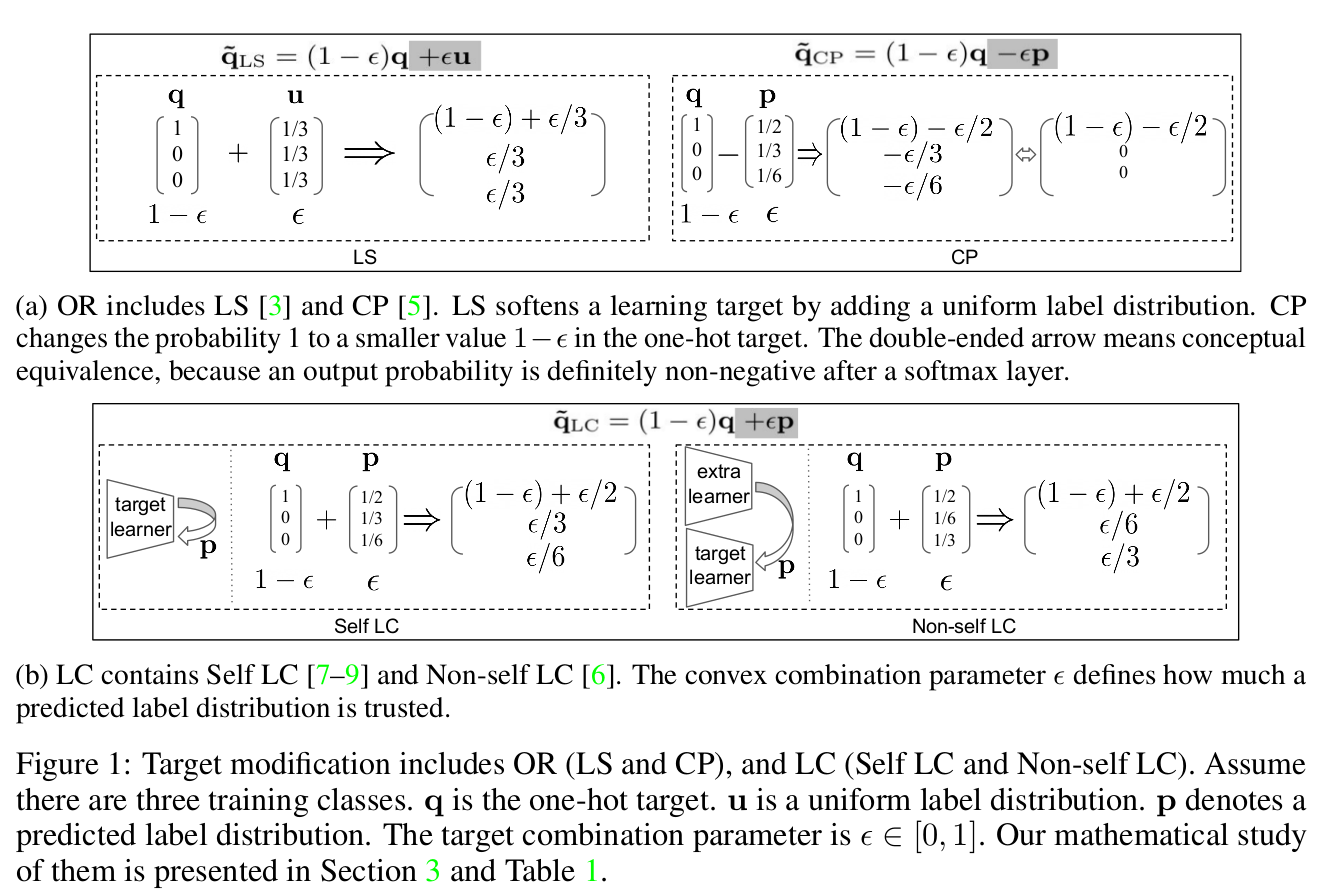
Target modification includes OR (LS and CP), and LC (Self LC and Non-self LC). Self LC is the most appealing because it requires no extra learners to revise learning targets, being free!
Summary of CCE, LS, CP and LC from the angle of target modification, entropy and KL divergence.
In Self LC, a core question is not well answered:
\(\textit{How much do we trust a learner to leverage its knowledge?}\)
Underlying Principle of ProSelfLC
When a learner starts to learn, it trusts the supervision from human annotations.
This idea is inspired by the paradigm that deep models learn simple meaningful patterns before fitting noise, even when severe label noise exists in human annotations [1];
As a learner attains confident knowledge as time goes, we leverage its confident knowledge to correct labels.
This is surrounded by minimum entropy regularisation, which has been widely evaluated in unsupervised and semi-supervised scenarios [10, 2].
Mathematical Details of ProSelfLC
Beyond semantic class: the similarity structure defined by a label distribution.
Human annotations and predicted label distributions, which should we trust more?
Design Reasons of ProSelfLC
Regarding \(g(t)\), in the earlier learning phase, i.e., \(t < \Gamma/2\), \(g(t) < 0.5 \Rightarrow \epsilon_{\mathrm{ProSelfLC}} < 0.5, \forall \mathbf{p}\), so that the human annotations dominate and ProSelfLC only modifies the similarity structure. This is because when a learner does not see the training data for enough times, we assume it is not trained well, which is the most elementary concept in deep learning. Most importantly, more randomness exists at the earlier phase, as a result, the learner may output a wrong confident prediction. In our design, \(\epsilon_{\mathrm{ProSelfLC}} < 0.5, \forall \mathbf{p}\) can assuage the bad impact of such unexpected cases. When it comes to the later learning phase, i.e., \(t > \Gamma/2\), we have \(g(t) > 0.5\), which means overall we give enough credits to a learner as it has been trained for more than the half of total iterations.
Regarding \(l(\mathbf{p})\), we discuss its effect in the later learning phase when it becomes more meaningful. If \(\mathbf{p}\) is not confident, \(l(\mathbf{p})\) will be large, then \(\epsilon_{\mathrm{ProSelfLC}}\) will be small, which means we choose to trust a one-hot annotation more when its prediction is of high entropy, so that we can further reduce the entropy of output distributions}. In this case, ProSelfLC only modifies the similarity structure. Beyond, when \(\mathbf{p}\) is highly confident, there are two fine cases: If \(\mathbf{p}\) is consistent with \(\mathbf{q}\) in the semantic class, ProSelfLC only modifies the similarity structure too; If they are inconsistent, ProSelfLC further corrects the semantic class of a human annotation.
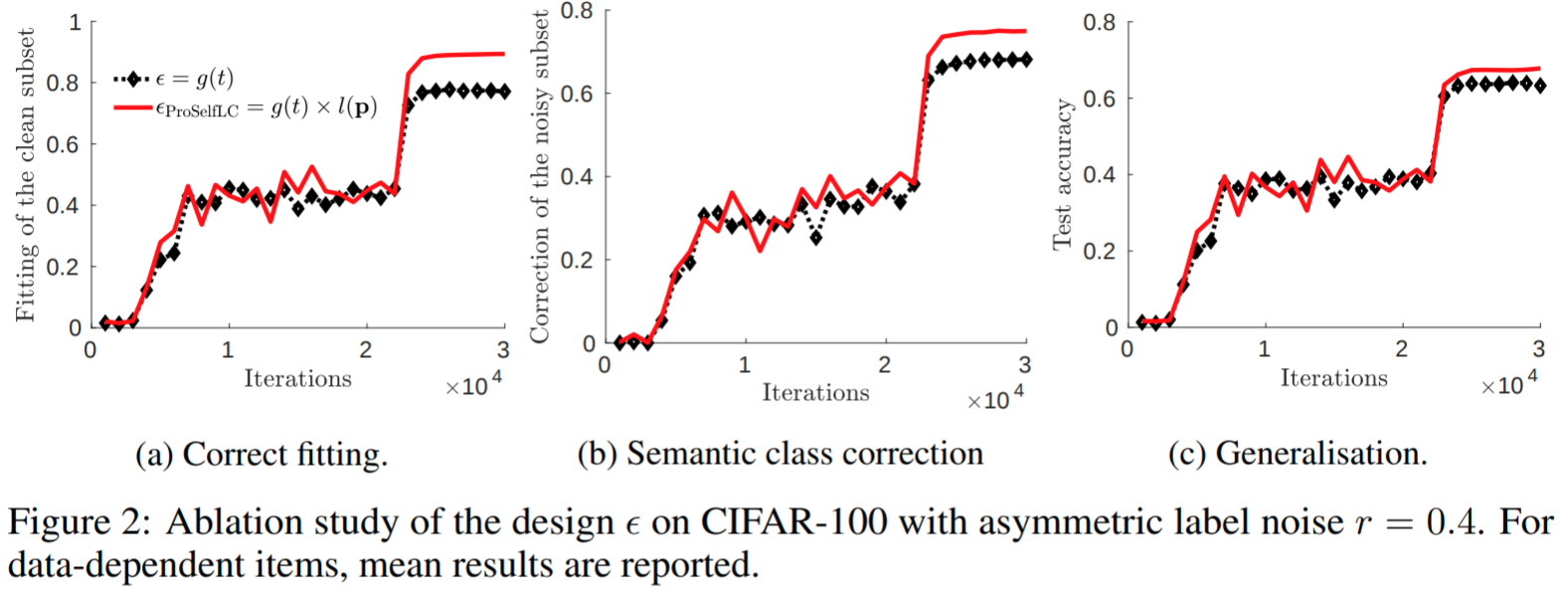
Ablation study on the design of ProSelfLC, where \(\epsilon_{\mathrm{ProSelfLC}}\) consistently performs the best when multiple metrics are reported.
Case analysis on the design of ProSelfLC.
Correct the similarity structure for every data point in all cases. Given any data point \(\mathbf{x}\), by a convex combination of \(\mathbf{p}\) and \(\mathbf{q}\), we add the information about its relative probabilities of being different training classes using the knowledge of a learner itself.
Revise the semantic class of an example only when the learning time is long and its prediction is confidently inconsistent. As highlighted in Table 2, only when two conditions are met, we have \(\epsilon_{\mathrm{ProSelfLC}} > 0.5\) and \(\argmax\nolimits_j \mathbf{p}(j|\mathbf{x}) \neq \argmax\nolimits_j \mathbf{q}(j|\mathbf{x})\), then the semantic class in $\mathbf{\tilde{q}_{\mathrm{ProSelfLC}}}$ is changed to be determined by \(\mathbf{p}\). For example, we can deduce \(\mathbf{p} = [0.95, 0.01, 0.04], \mathbf{q} = [0, 0, 1], \epsilon_{\mathrm{ProSelfLC}}=0.8 \Rightarrow \mathbf{\tilde{q}_{\mathrm{ProSelfLC}}}=(1- \epsilon_{\mathrm{ProSelfLC}}) \mathbf{q}+\epsilon_{\mathrm{ProSelfLC}} \mathbf{p}=[0.76, 0.008, 0.232]\). Theoretically, ProSelfLC also becomes robust against long time being exposed to the training data, so that early stopping is not required.
Deep models learn simple meaningful patterns before fitting noise, even when severe label noise exists in human annotations.
2019-Derivative manipulation for general example weighting — @article{wang2019derivative, title={Derivative Manipulation for General Example Weighting}, author={Wang, Xinshao and Kodirov, Elyor and Hua, Yang and Robertson, Neil M}, journal={arXiv preprint arXiv:1905.11233}, year={2019} } —
Arpit, D., Jastrz ̨ebski, S., Ballas, N., Krueger, D., Bengio, E., Kanwal, M.S., Maharaj, T., Fischer, A., Courville, A., Bengio, Y., Lacoste-Julien, S.: A closer look at memorization in deep networks. In: ICML. (2017)