An Extremely Simple and Principled Solution for Robust Learning under Arbitrary Anomalies
in Blogs

General applicability: Label noise (semantic noise), outliers, heavy perceptual data noise, etc.
It is reasonable to assume that there is semantic noise in large-scale training datasets:
- Class labels may be missing.
- The labelling process may be subjective.
Label noise is one of the most explicit cases where some observations and their labels are not matched in the training data. In this case, it is quite crucial to make your models learn meaningful patterns instead of errors.
Introduction
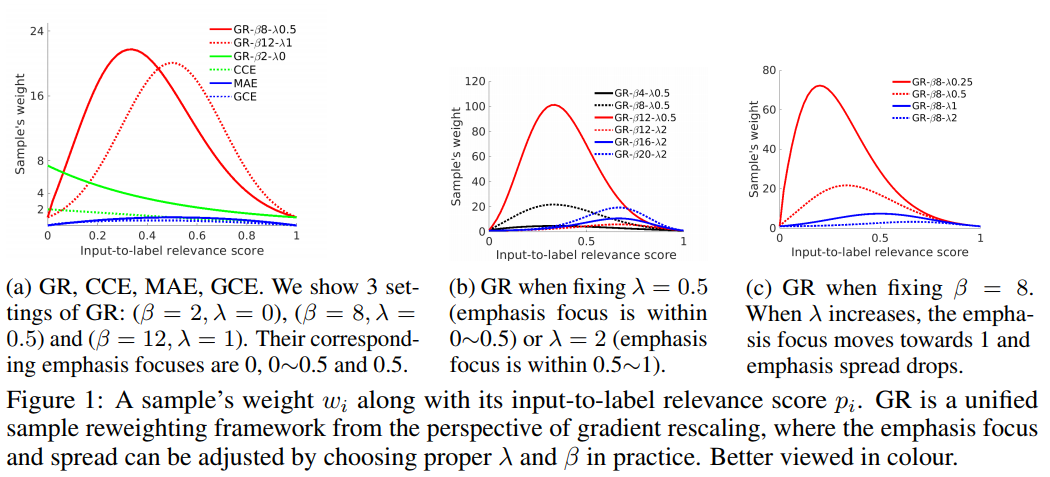
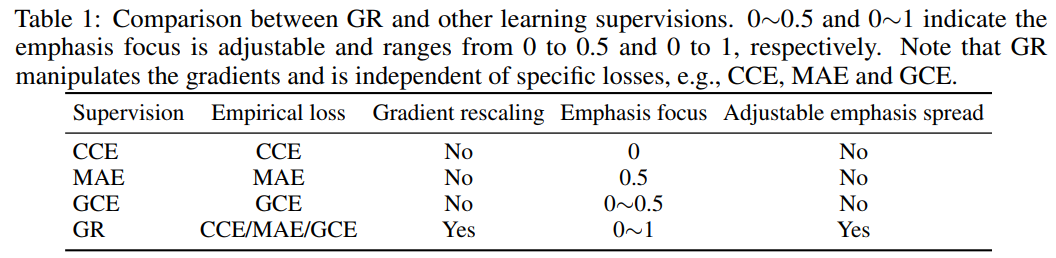
Main contribution: Intuitively and principally, we claim that two basic factors, what examples get higher weights (emphasis focus) and how large variance over examples’ weights (emphasis spread), should be babysit simultaneously when it comes to sample differentiation and reweighting. Unfortunately, these two intuitive and indispensable factors are not studied together in the literature.
What training examples should be focused and how much more should they be emphasised when training DNNs under label noise?
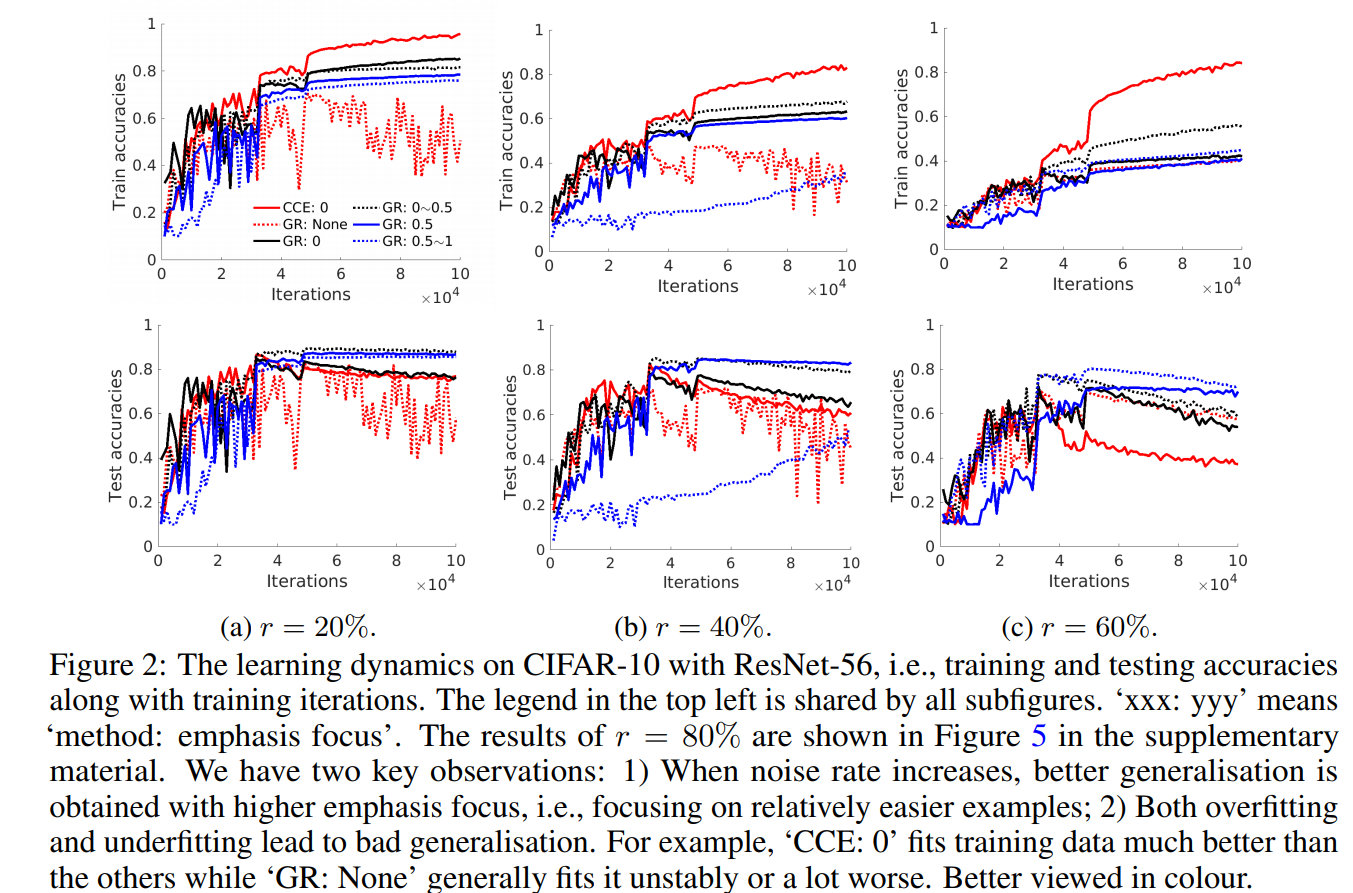
When noise rate is higher, we can improve a model’s robustness by focusing on relatively less difficult examples.
More comments and comparison with related work
Paper reading about outlier detection and robust inference
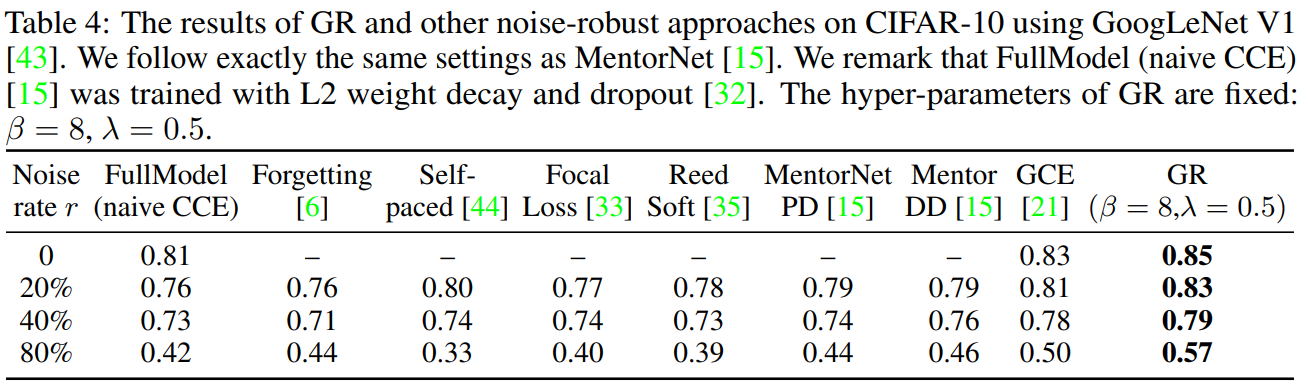
Effective (Qualitative and Quantitative Results)
Please see our paper:
- Outperform existing work on synthetic label noise;
- Outperform existing work on unknown real-world noise.



Extremely Simple
Without advanced training strategies: e.g.,
a. Iterative retraining on gradual data correction
b. Training based on carefully-designed curriculums
…
Without using extra networks: e.g.,
a. Decoupling” when to update” from” how to update”
b. Co-teaching: Robust training of deep neural networks with extremely noisy labels
c. Mentornet: Learning datadriven curriculum for very deep neural networks on corrupted labels
…
Without using extra validation sets for model optimisation: e.g.,
a. Learning to reweight examples for robust deep learning
b. Mentornet: Learning datadriven curriculum for very deep neural networks on corrupted labels
c. Toward robustness against label noise in training deep discriminative neural networks
d. Learning from noisy large-scale datasets with minimal supervision.
e. Learning from noisy labels with distillation.
f. Cleannet: Transfer learning for scalable image classifier training with label noise
…
Without data pruning: e.g.,
a. Generalized cross entropy loss for training deep neural networks with noisy labels.
…
Without relabelling: e.g.,
a. A semi-supervised two-stage approach to learning from noisy labels
b. Joint optimization framework for learning with noisy labels
…
Citation
Please kindly cite us if you find our work useful and inspiring.
@article{wang2019emphasis,
title={Emphasis Regularisation by Gradient Rescaling for Training Deep Neural Networks Robustly},
author={Wang, Xinshao and Hua, Yang and Kodirov, Elyor and Robertson, Neil},
journal={arXiv preprint arXiv:1905.11233},
year={2019}
}
References
Eran Malach and Shai Shalev-Shwartz. Decoupling” when to update” from” how to update”. In NIPS, 2017.
Bo Han, Quanming Yao, Xingrui Yu, Gang Niu, Miao Xu, Weihua Hu, Ivor Tsang, and Masashi Sugiyama. Co-teaching: Robust training of deep neural networks with extremely noisy labels. In NIPS, 2018
Lu Jiang, Zhengyuan Zhou, Thomas Leung, Li-Jia Li, and Li Fei-Fei. Mentornet: Learning datadriven curriculum for very deep neural networks on corrupted labels. In ICML, 2018.
Mengye Ren, Wenyuan Zeng, Bin Yang, and Raquel Urtasun. Learning to reweight examples for robust deep learning. In ICML, 2018.
Arash Vahdat. Toward robustness against label noise in training deep discriminative neural networks. In NIPS, 2017.
Andreas Veit, Neil Alldrin, Gal Chechik, Ivan Krasin, Abhinav Gupta, and Serge Belongie. Learning from noisy large-scale datasets with minimal supervision. In CVPR, 2017.
Yuncheng Li, Jianchao Yang, Yale Song, Liangliang Cao, Jiebo Luo, and Li-Jia Li. Learning from noisy labels with distillation. In ICCV, 2017.
Kuang-Huei Lee, Xiaodong He, Lei Zhang, and Linjun Yang. Cleannet: Transfer learning for scalable image classifier training with label noise. In CVPR, 2018.
Zhilu Zhang and Mert R Sabuncu. Generalized cross entropy loss for training deep neural networks with noisy labels. In NIPS, 2018.
Yifan Ding, Liqiang Wang, Deliang Fan, and Boqing Gong. A semi-supervised two-stage approach to learning from noisy labels. In WACV, 2018.
Hwanjun Song, Minseok Kim, and Jae-Gil Lee. Selfie: Refurbishing unclean samples for robust deep learning. In ICML, 2019.
Daiki Tanaka, Daiki Ikami, Toshihiko Yamasaki, and Kiyoharu Aizawa. Joint optimization framework for learning with noisy labels. In CVPR, 2018.