Papers on Video Person ReID
Recent papers on video person reid.
ICCV 2019: Co-segmentation Inspired Attention Networks for Video-based Person Re-identification
Why Video: Video-based Re-ID approaches have gained significant attention recently since a video, and not just an image, is often available.
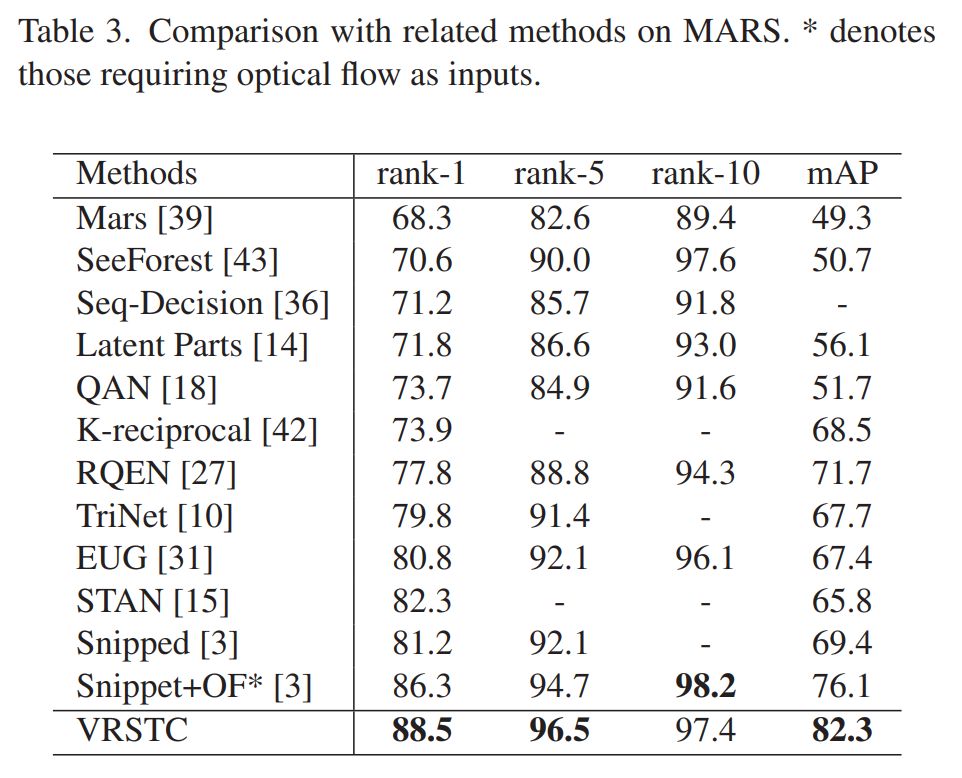
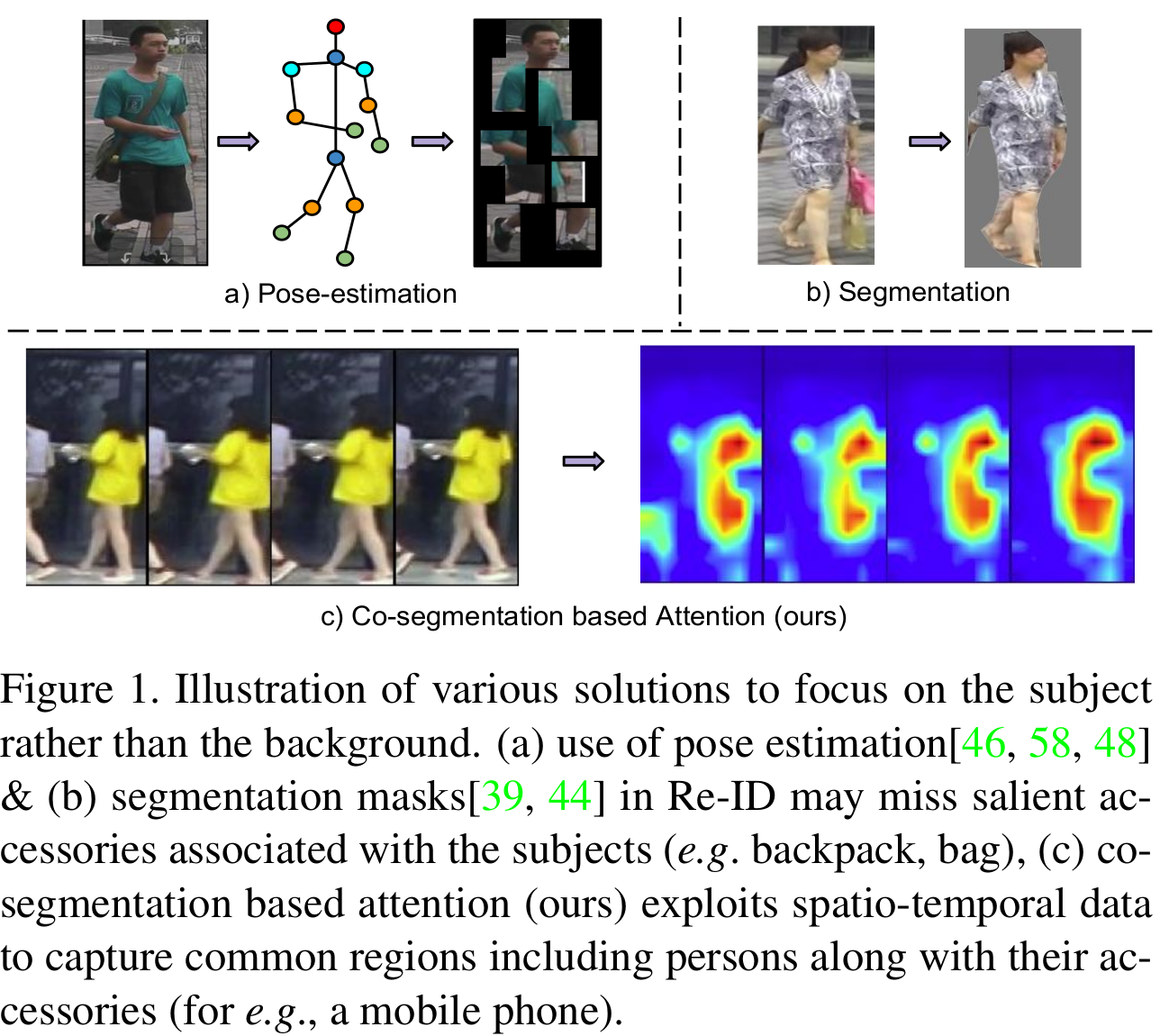
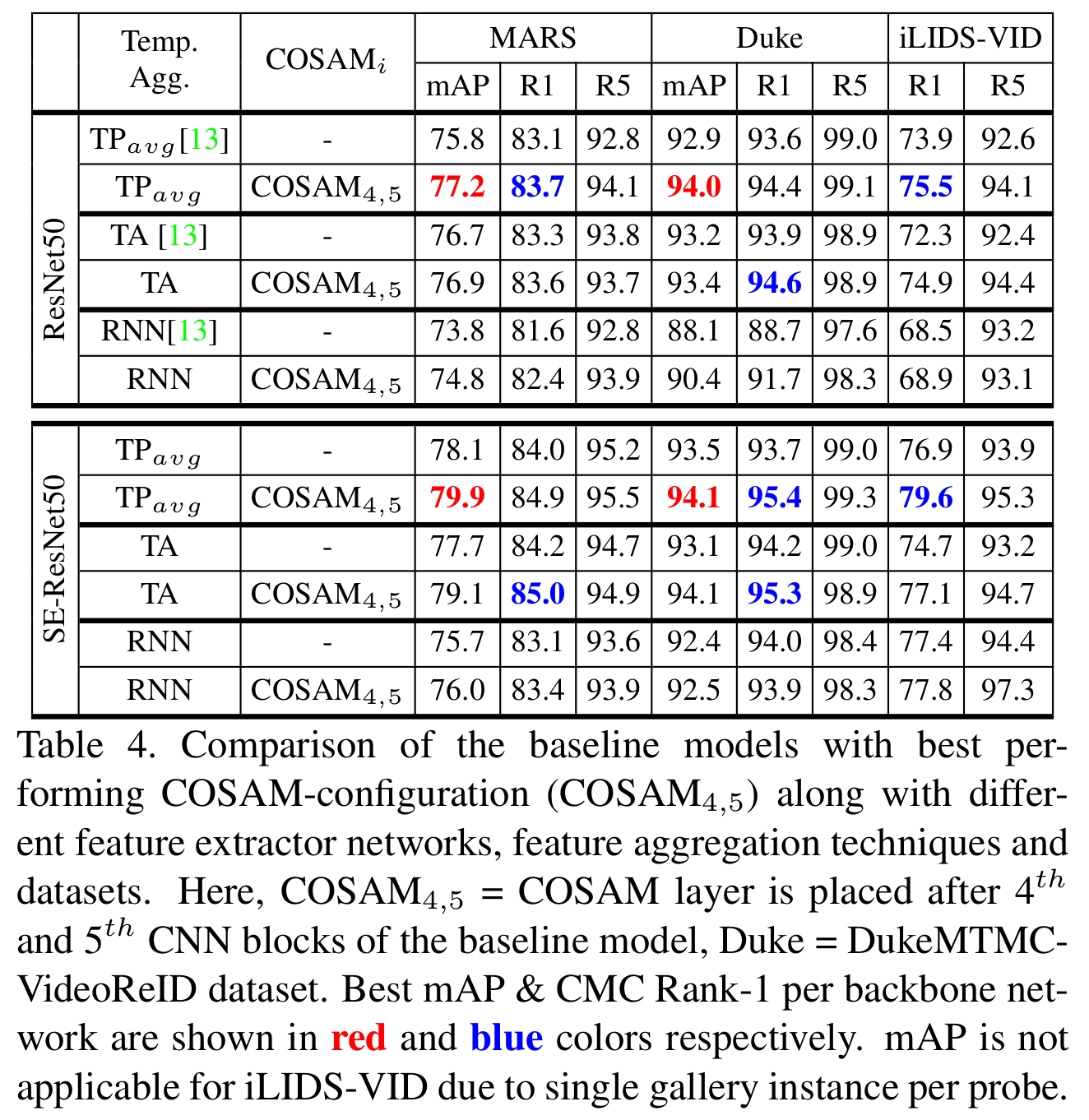
We propose a novel Co-segmentation in- spired video Re-ID deep architecture and formulate a Co- segmentation based Attention Module (COSAM) that activates a common set of salient features across multiple frames of a video via mutual consensus in an unsupervised manner. As opposed to most of the prior work, our approach is able to attend to person accessories along with the person. Our plug-and-play and interpretable COSAM module applied on two deep architectures (ResNet50, SE-ResNet50) outperform the state-of-the-art methods on three benchmark datasets

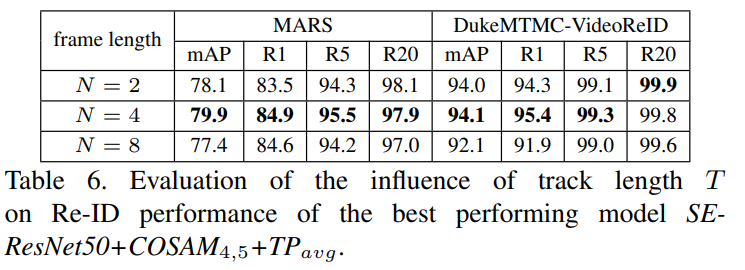
- Every video of the person is split into multiple non-overlapping video-snippets of length N frames and each snippet is passed through the network to obtain a snippet-level descriptor.
- The video-snippet level descriptors are averaged to get the video-level descriptor. Then, these video-level descriptors are compared using the L2 distance to calculate the CMC and mAP performances.
- Snippet-level idea is bad: 1) if the video is too short; 2) if the video is too long.
- An in-depth analysis by plugging in multiple COSAMs at various locations is detailed in the Supplementary Material.
ICCV 2019: Global-Local Temporal Representations For Video Person Re-Identification
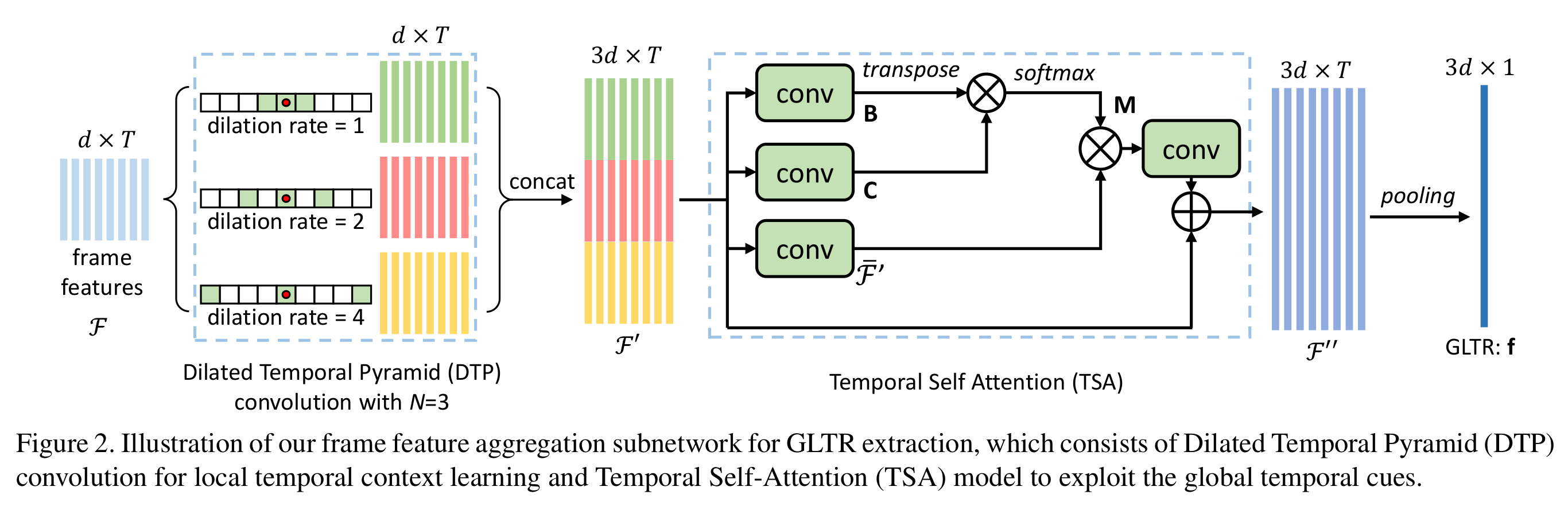
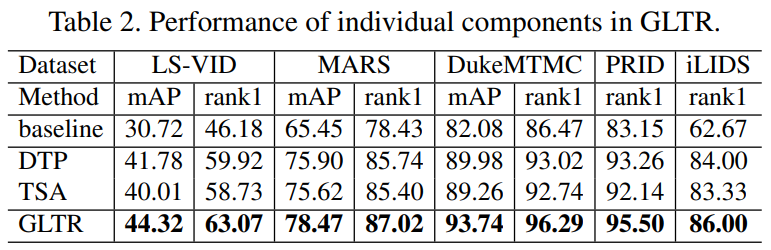
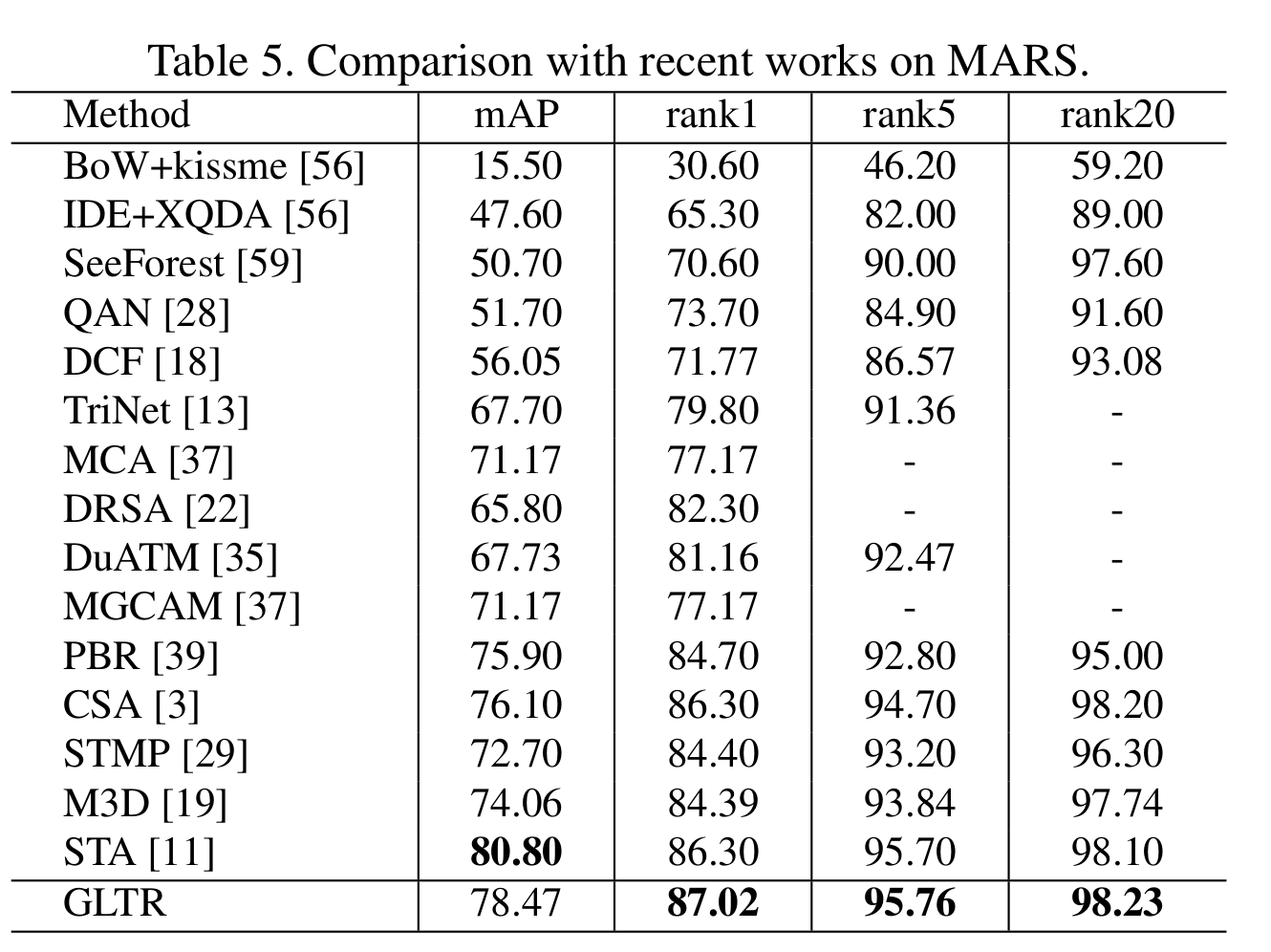
Abstract: This paper proposes the Global-Local Temporal Repre- sentation (GLTR) to exploit the multi-scale temporal cues in video sequences for video person Re-Identification (ReID). GLTR is constructed by first modeling the short-term temporal cues among adjacent frames, then capturing the long-term relations among inconsecutive frames. Specifically, the short-term temporal cues are modeled by parallel dilated convolutions with different temporal dilation rates to represent the motion and appearance of pedestrian. The long-term relations are captured by a temporal self-attention model to alleviate the occlusions and noises in video sequences. The short and long-term temporal cues are aggregated as the final GLTR by a simple single-stream CNN. GLTR shows substantial superiority to existing features learned with body part cues or metric learning on four widely-used video ReID datasets. For instance, it achieves Rank-1 Accuracy of 87.02% on MARS dataset without reranking, better than current state-of-the art.
Dilated Temporal Pyramid (DTP) Convolution for local temporal context learning
Temporal Self-Attention (TSA) for exploiting the global temporal cues.

- We employ standard ResNet50 [12] as the backbone for frame feature extraction.
- Input images are resized to 256×128.
- All models are trained and finetuned with PyTorch.
- For 2D CNN training, each batch contains 128 images.
- For DTP and TSA training, we sample 16 adjacent frames from each sequence as input for each training epoch. The batch size is set as 10.
All models are trained with only softmax loss.
Testing: We use 2D CNN to extract a d=128-dim feature from each video frame, then fuse frame features into GLTR using the network illustrated in Fig. 2. The video feature is finally used for person ReID with Euclidean distance.
- CSA: competitive snippet aggregation
- STMP-Inception-v3: Liu et al. [29] propose a recurrent architecture to aggregate the frame-level representations and yield a sequence-level human feature representation. RNN introduces a certain number of fully-connected layers and gates for temporal cue modeling, making it complicated and difficult to train. STMP [29] introduces a complex recurrent network and uses part cues and triplet loss.
- M3D-ResNet50: 3D convolution directly extracts spatial-temporal features through end-to-end CNN training. Recently, deep 3D CNN is introduced for video representation learning. Tran et al. [41] propose C3D networks for spatial-temporal feature learning. Qiu et al. [32] factorize the 3D convolutional filters into spatial and temporal components, which yield performance gains. Li et al. [19] build a compact Multiscale 3D (M3D) convolution network to learn multi-scale temporal cues. Although 3D CNN has exhibited promising performance, it is still sensitive to spatial misalignments and needs to stack a certain number of 3D convolutional kernels, resulting in large parameter overheads and increased difficult for CNN optimization. M3D [19] use 3D CNN to learn the temporal cues, hence requires higher computational complexity.
- STA-ResNet50: STA introduces multi-branches for part feature learning and uses triplet loss to promote the performance. Compared with those works, our method achieves competitive performance with simple design., e.g., we extract global feature with basic backbone and train only with the softmax loss.
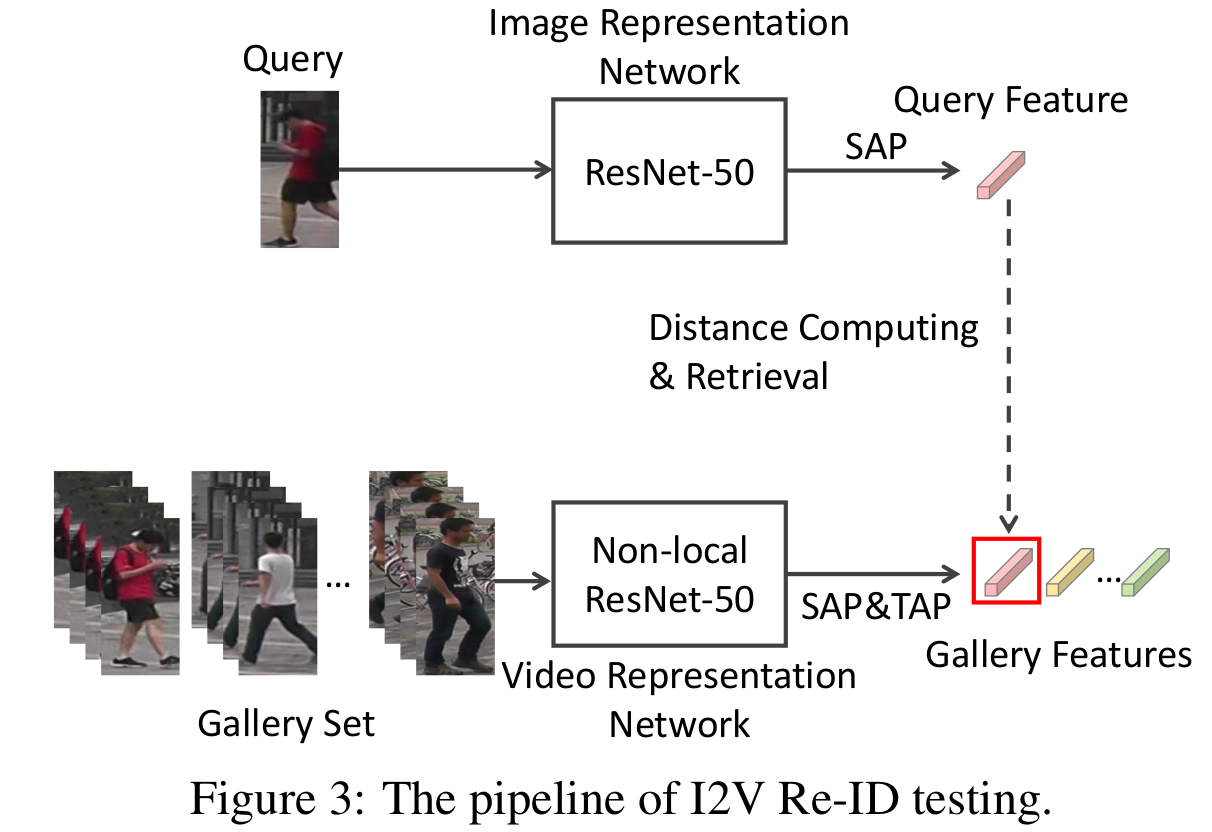
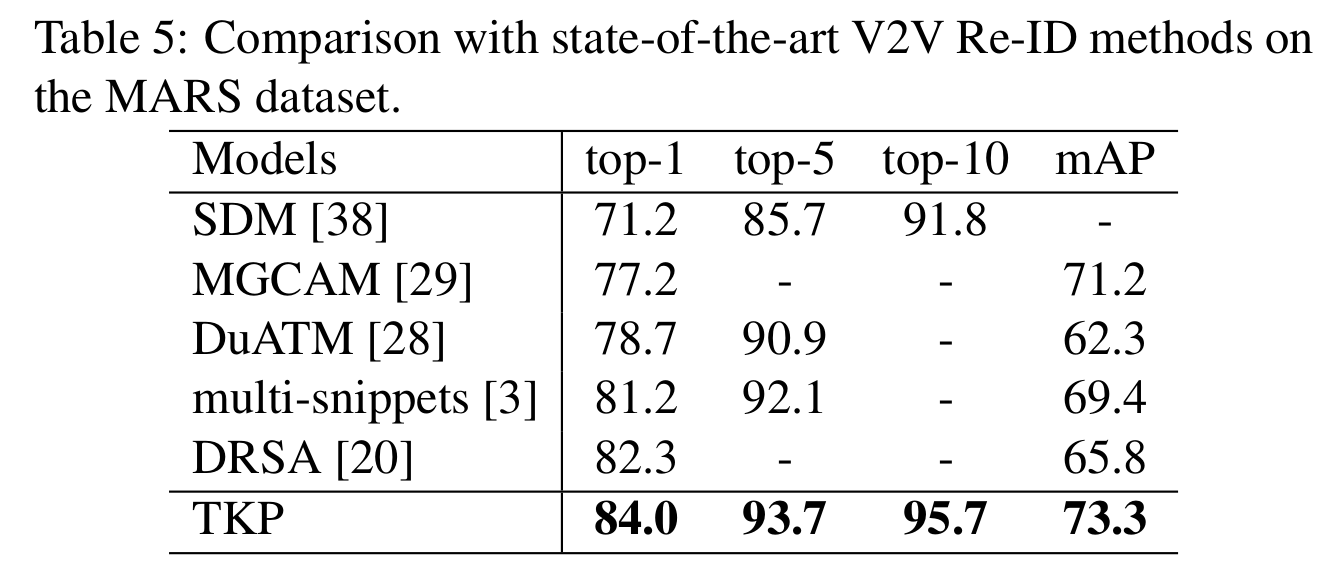
ICCV 2019: Temporal Knowledge Propagation for Image-to-Video Person Re-identification
In many scenarios of Person Re-identification (Re-ID), the gallery set consists of lots of surveillance videos and the query is just an image, thus Re-ID has to be conducted be- tween image and videos
Specifically, given the input videos, we enforce the image representation network to fit the outputs of video representation network in a shared feature space. With back propagation, temporal knowledge can be transferred to enhance the image features and the information asymmetry problem can be alleviated.
Note that both image and video networks use ResNet50 as backbone. The only difference is that video network add extra non-local blocks to model temporal information. Given the same inputs, TKP loss enforces these two networks to output similar features. Obviously, the weights of additional non-local blocks being 0 is the optimal solution of minimizing TKP loss. In that case, the non-local blocks can not capture any temporal information. So updating video network by TKP deteriorates modeling temporal knowledge. Unless specified, in our emperiments, $L^F_{TKP}$ and $L^D_{TKP}$ are not back-propagated through the video representation network during model training.
Objective functions:
- Classification Loss: We build two shared weights classifiers to map the image features and video features to a shared identity space.
Integrated Triplet Loss: We also use triplet loss with hard sample mining [10] to constrain the relative sample distances in the shared feature space. Specifically, we integrate four kinds of triplet losses, image-to-video (I2V), video-to-image (V2I), image-to-image (I2I) and video-tovideo (V2V) triplet losses. The final triplet loss LT is defined as:
$L_T = L_{I2V} + L_{V2I} + L_{I2I} + L_{V2V}$
The final objective function is formulated as the combination of classification loss, integrated triplet loss and the proposed TKP loss:
$L = L_C + L_T + L^D_{TKP} + L^F_{TKP}$
- We pre-train ResNet-50 on ImageNet [26] and adopt the method in [33] to initialize the non-local blocks.
- During training, we randomly sample 4 frames with a stride of 8 frames from the original full-length video to form an input video clip. For the original video less than 32 frames, we duplicate it to meet the length.
- For iLIDS-VID, we first pre-train the model on large-scale dataset and then fine-tune it on iLIDS- VID following [31].
- In the test phase, the query image features are extracted by image representation model. For each gallery video, we first split it into several 32-frame clips. For each clip, we utilize video representation model to extract video represen- tation. The final video feature is the averaged representation of all clips.
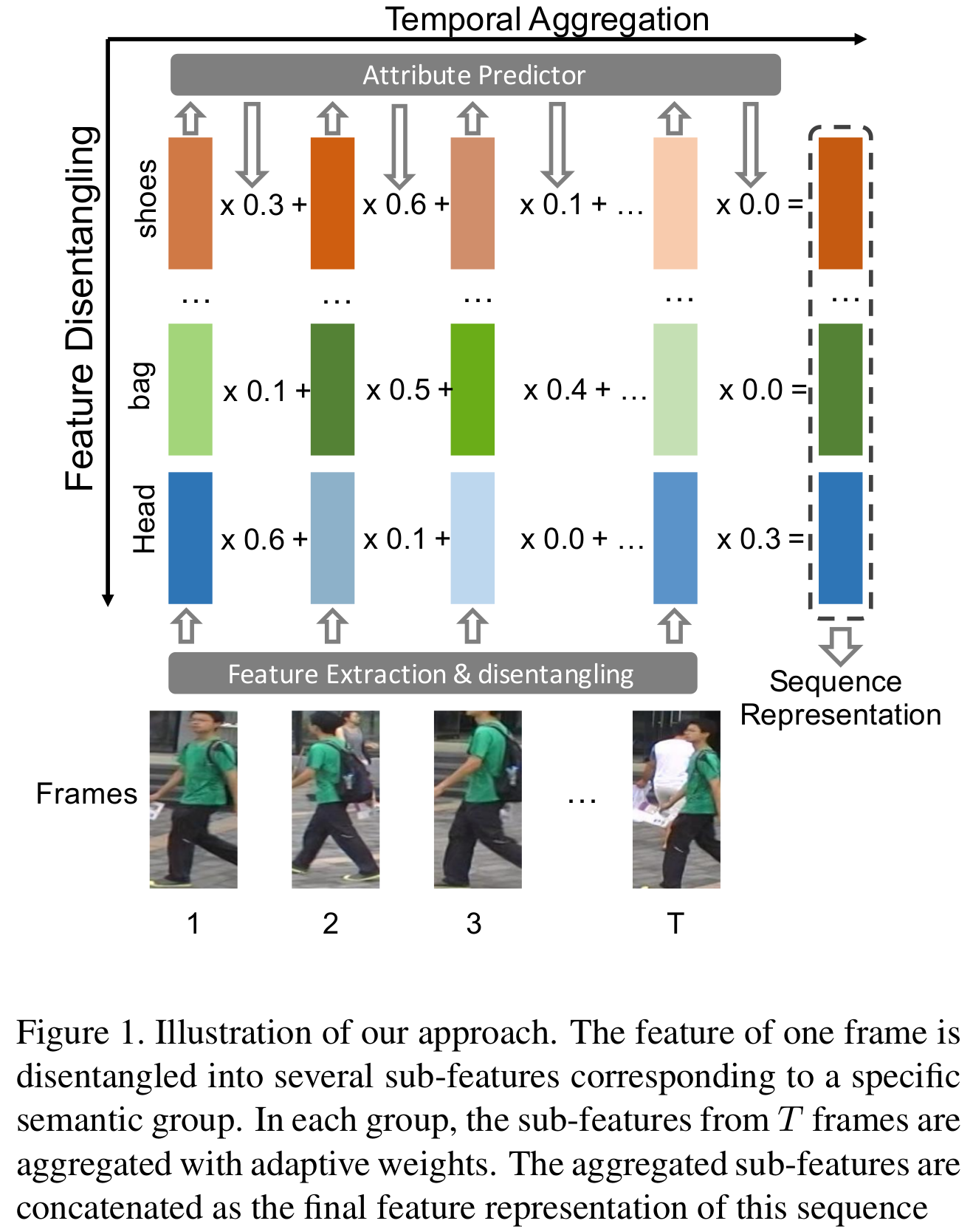
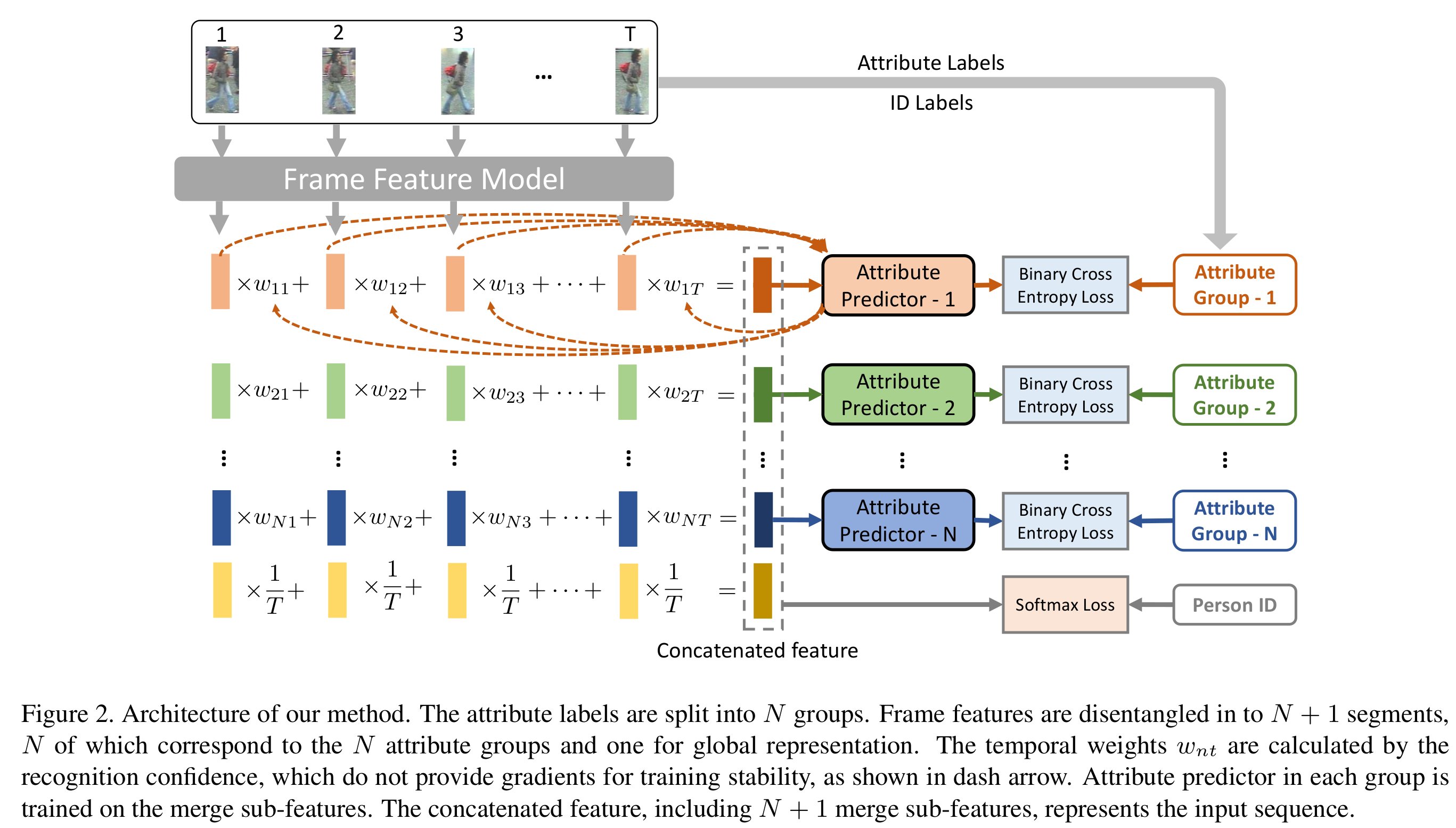
CVPR 2019: Attribute-Driven Feature Disentangling and Temporal Aggregation for Video Person Re-Identification
- In this paper, we propose an attribute-driven method for feature disentangling and frame re-weighting. The features of single frames are disentangled into groups of sub-features, each corre- sponds to specific semantic attributes. The sub-features are re-weighted by the confidence of attribute recognition and then aggregated at the temporal dimension as the final rep- resentation. By means of this strategy, the most informa- tive regions of each frame are enhanced and contributes to a more discriminative sequence representation. Extensive ablation studies verify the effectiveness of feature disentan- gling as well as temporal re-weighting. The experimental results on the iLIDS-VID, PRID-2011 and MARS datasets demonstrate that our proposed method outperforms exist- ing state-of-the-art approaches.
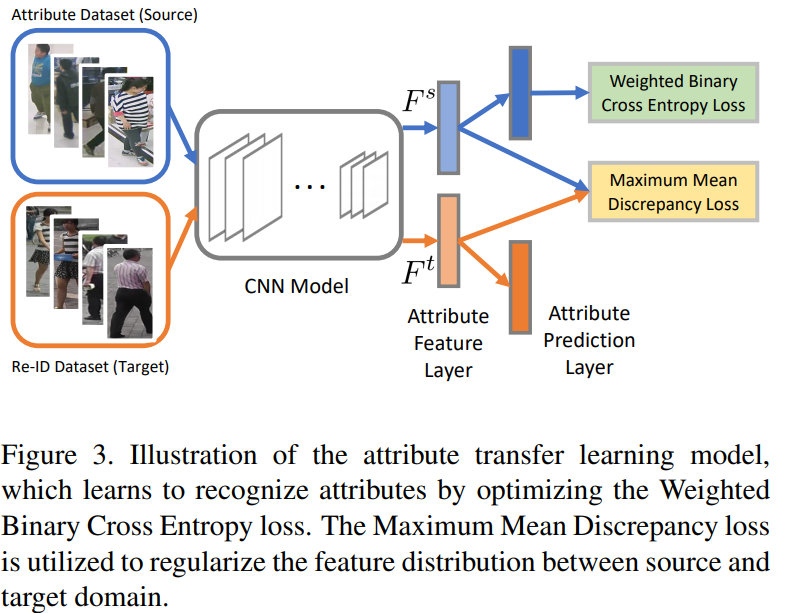
- Input images are first resized to 144 × 288 and cropped at 128 × 256. For the data augmentation, we use random crops with random horizontal mirroring for training and a single center crop for testing.
- We use SGD to train our model and the batch size is 32. The sequence length is set to T = 8. The learning rate starts from 0.05 and is divided by 10 every 40 epochs to train the model for 100 epochs.
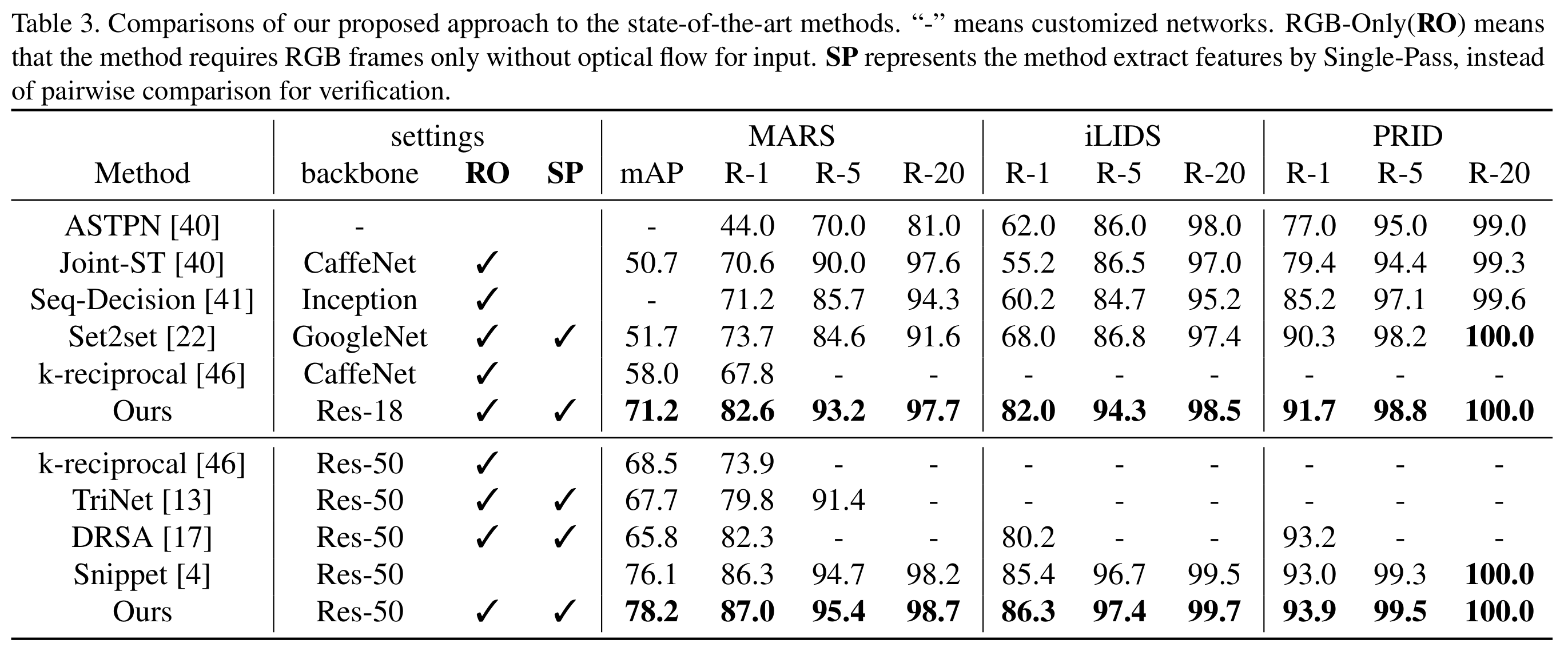
- In real-world applications, computational efficiency is equally important to performance. It is worth noting that Snippet and ASTPN require optical flow as input to provide motion features. However, the calculation of optical flow is very time-consuming and is hard to be applied in real-time system.
- Some existing methods perform pairwise comparison to calculate the similarity between query and gallery sequences, e.g. a pair of sequence are input to the network for verification. This strategy is impracticable in large-scale scenarios because all the gallery sequences need to be calculated once for each query. An efficient practice is extracting features of large gallery set once in an off- line way and sorting them by Euclidean distances in fea- ture space when given a query sequence.
- Our proposed method, which does not require optical flow and pairwise comparison, is more suitable for real-world applications. Based on the same “Res50 + RGB-Only + Sing-Pass” set- ting, our method significantly improves the mAP on MARS by 10.5% and boosts the CMC-1 by 4.7%/6.1%/0.7% on the three dataset.
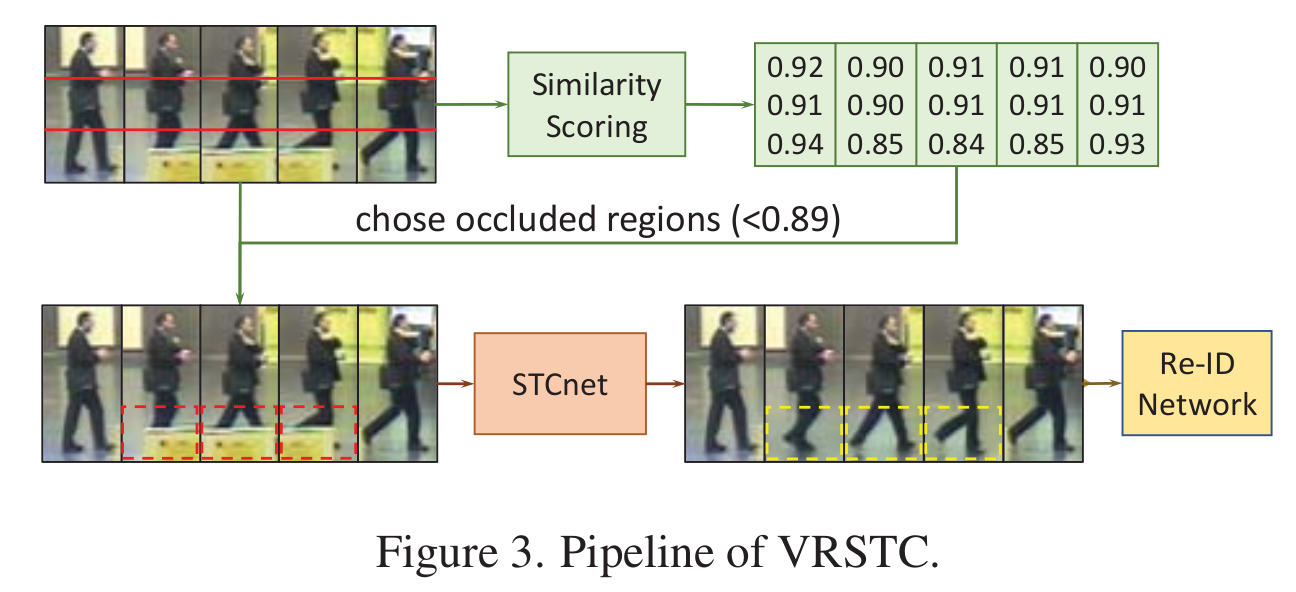
CVPR 2019: VRSTC: Occlusion-Free Video Person Re-Identification
Different from most previous works that discard the occluded frames, STCnet can recover the appearance of the occluded parts. For one thing, the spatial structure of a pedestrian frame can be used to predict the occluded body parts from the unoccluded body parts of this frame. For another, the temporal patterns of pedestrian sequence provide important clues to generate the contents of occluded parts. With the spatiotemporal information, STCnet can recover the appearance for the oc- cluded parts, which could be leveraged with those unoc- cluded parts for more accurate video re-ID.
- We train ResNet-50 with cross-entropy loss to be the ID guider of STCNet.
In training term, four-frame input tracks are cropped out from an input sequence. The frame features are extracted by ResNet-50, then the average temporal pooling is used to obtain the sequence feature. Input images are resized to 256 × 128.
We embed the non-local block [29] in the re-ID network to capture temporal dependency of input sequence.
Locating occluded regions. With the pretrained re-ID network as feature extractor, we use the similarity scoring mechanism to generate the score for each frame region. We regard the regions whose scores are lower than τ as the occluded regions, and we define the frames without occluded regions as the unoccluded frames. In our experiment, τ is set to 0.89.
The occluded regions of the frames in raw re-ID dataset are replaced with the regions generated by STCnet to form a new dataset. Then the re-ID network is trained and tested with the new dataset.
In order to verify the effectiveness of STCnet as a kind of data enhancement method, we use a simple re-ID network with average temporal pooling and the cross entropy loss.
- In order to capture temporal dependency, we embed the non-local blocks [29] into the re-ID network. Different from the previous works that only build temporal dependency in the end, the non-local blocks can be inserted into the earlier part of deep neural networks. This allows us to build a richer hierarchical temporal dependency that combines both non-local and local information.